[OS] 캐시 메모리
1. 캐시 메모리
- 캐시는 CPU와 메모리 사이의 속도 차이를 줄이기 위한 고속 메모리
- 고속 메모리인 만큼 비싸고, 용량이 작으며 컴퓨터 성능에 영향을 미침
- 투명성 Transparency
- 프로그래머는 캐시를 조작할 수 있는 명령어가 없음
- 하드웨어 단에서 알아서 동작!
- 외부에서 보면 캐시가 없는 것과 같음
- Cache hit and miss
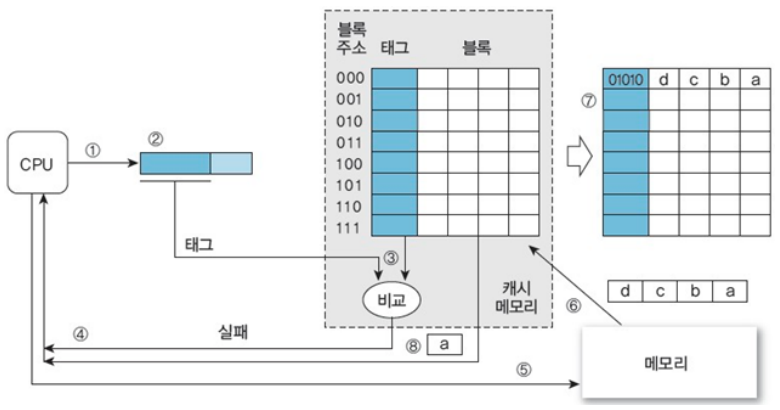
- 만약 캐시에 CPU가 원하는 정보가 있다면 적중(Hit)
만약 캐시에 CPU가 원하는 정보가 없다면 실패(Miss)
- 적중률 = (캐시 적중횟수) / (전체 메모리 참조횟수)
- 평균 access 타임
- $T_{a} = H \times T_{c} + (1-H) \times T_{m}$
- $a$: access
- $c$: cache
- $m$: memory
- $T_{a} = H \times T_{c} + (1-H) \times T_{m}$
2. 캐시 인덱싱
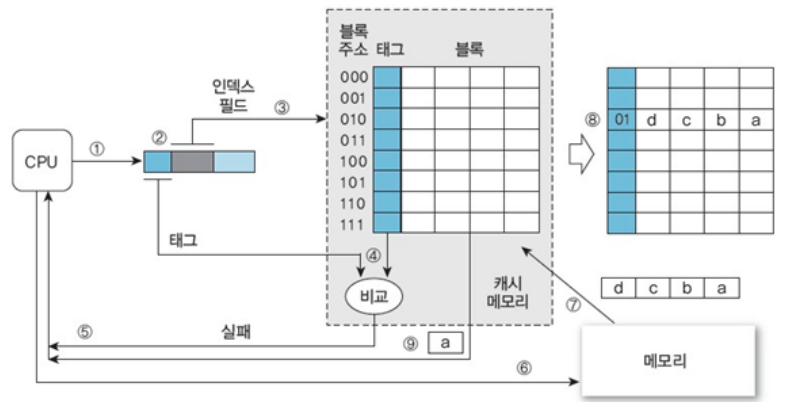
- 캐시는 블록(Block)으로 구성되어 있음.
- 각각의 블록은 데이터를 담고 있으며, 주소값을 키로써 접근
- 메모리를 블록 단위로 구분 한다는 것.
- modulo(나머지, mod) 연산을 통해 메모리 블록을 정해진 캐시 블록에만 사상
- 블록의 개수(Blocks)와 블록의 크기(Block size)가 캐시의 크기를 결정
- 각각의 블록은 데이터를 담고 있으며, 주소값을 키로써 접근
- 주소값 전체를 키로 사용하지는 않고, 그 일부만을 사용
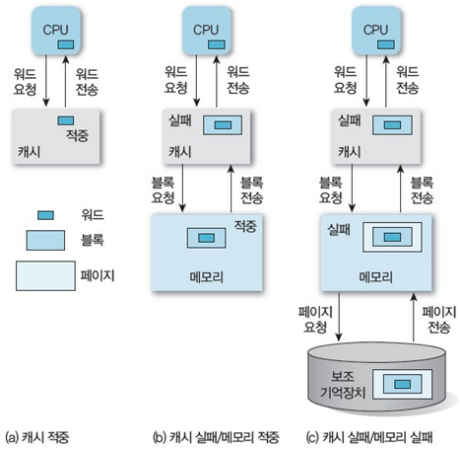
- e.g., 가령 블록 개수가 1024개이고, 블록 사이즈가 32바이트일 때, 32비트 주소가 주어진다면
- 전체 주소에서 하위 5비트를 오프셋(Offset)으로 사용
- 이후 10bit를 index로 사용 (why?)
- 서로 다른 데이터의 인덱스가 중복될 위험이 너무 큰 주소 인덱싱
- e.g., 가령 블록 개수가 1024개이고, 블록 사이즈가 32바이트일 때, 32비트 주소가 주어진다면
3. Tag matching
- 인덱스의 충돌을 줄이기 위해 주소값의 일부를 태그(Tag)로 사용
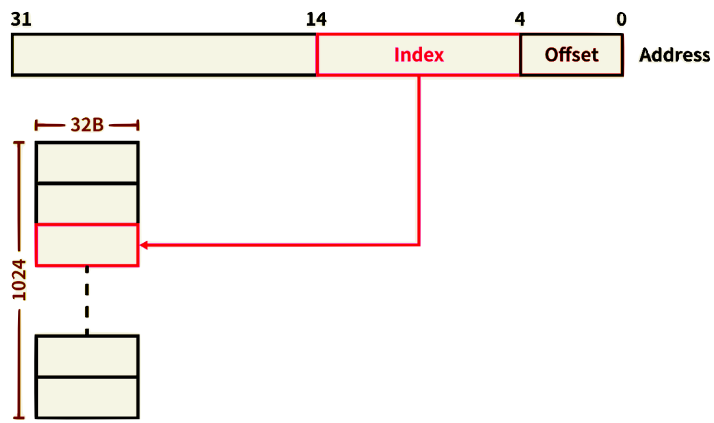
- 블록 개수가 1024개이고, 블록 사이즈가 32B, 32 bit 주소 0x000c14B8에 접근할 때,
- (0000 0000 0000 1100 0 001 0100 101 1 1000)
- 먼저 인덱스(0010100101)에 대응하는 태그 배열(Tag array)의 필드에 접근한다.
- 다음 태그 필드의 유효 비트(Valid bit)를 확인
- 유효 비트가 1이라면 태그 필드(00000000000011000)와 주소의 태그(00000000000011000)가 같은지 비교
- 비교 결과(true, 1)를 유효 비트(1)와 AND 연산한다.
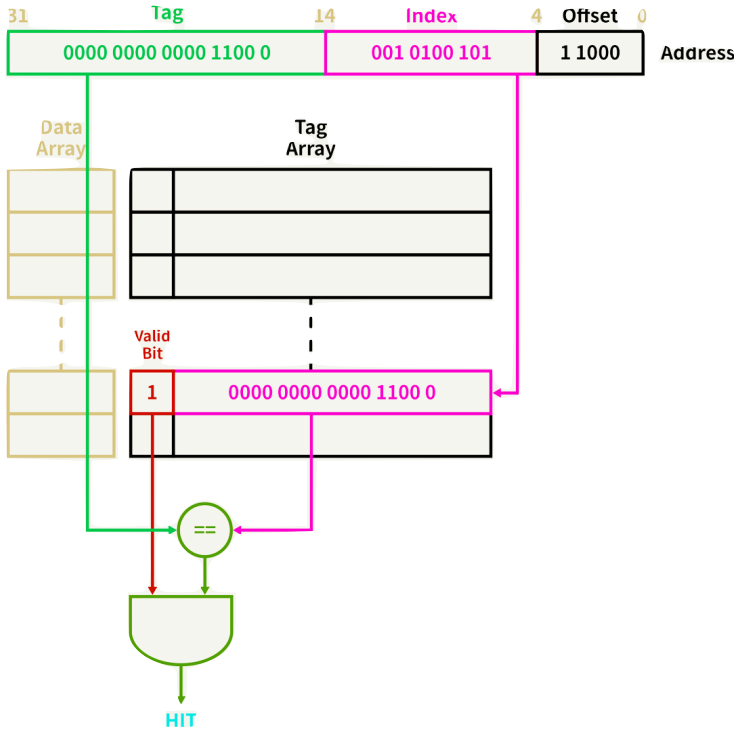
- 01 010 0000 에 대한 데이터 참조
- (T) (I) (offset)
태그 필터링 후 인덱스를 가져옴
- 태그와 인덱스가 거꾸로 되어있는 이유
- 만약 I T offset이라면 locality를 활용하지 못한다
- 주소에 대해 하위 3비트가 인덱스로 주어지면, 그것을 블록 주소로 사용한다.
- 블록 위치 식별자: 인덱스
- 블록 안에서 식별하는 것: 태그
- 서로 다른 블록으로 저장될 때 캐시 히트율이 높아진다.
- 만약 I T offset이라면 locality를 활용하지 못한다
- 단점
1
2
3
4
5
6
7
00 010
01 010
10 010
11 010
이라면? 나머지 태그 공간을 낭비. -> 해결책: 완전 연관 사상
4. Tag overhead
- 태그가 추가됨에 따라 더 많은 공간이 필요…
- 하지만 캐시의 사이즈는 변함이 없음 → 캐시 메모리의 용량을 얘기할 때는 주로 태그 메모리는 빼고, 데이터 메모리 용량만을 의미
- 예, 32KB 캐시는 태그와 관계없이 여전히 32KB 캐시
- 태그를 위한 공간은 블록 크기와 상관없는 오버헤드(Overhead)로 취급
- 1024개의 32B 블록으로 구성된 32KB 캐시의 태그 오버헤드
- 17bit tag + 1bit valid flag = 18bit.
- 18*1024 = 18Kb tags = 2.25 KB,
- i.e., 34.25/32 = 1.0703125, i.e., 약 7%의 오버헤드
- 그리고 Latency도 증가함
- 태그 배열에 접근해 히트를 확인, 2. 데이터 배열에 접근해 데이터를 가져오기 때문
- 따라서 두 과정을 병렬적으로 → 태그 히트를 검색함과 동시에 미리 데이터를 가져옴.
5. Tag matching 장단점
5.1. 장점
- 태그의 길이가 짧다
- CPU 태그를 하나의 캐시 태그와 비교하기 때문에 하나의 비교기만 있으면 가능
- 따라서 하드웨어 구현이 단순하고 접근 속도가 빠르다.
5.2. 단점
- 적중률이 저조
- 특히 동일한 캐시 블록에 사상되는 다른 메모리 블록을 번갈아 참조할 때 캐시 블록에 심각한 충돌이 발생하여 적중률이 급격히 낮음 (ping-pong 문제)
- 그래서 대용량 캐시 메모리일 경우에만 주로 직접 사상 방식을 이용
6. Associative Cache
추가 예정
7. 완전 연관 사상
7.1. 장점
• 직접 연관 사상보다 적중률이 높음 (시간적 locality)
7.2. 단점
• CPU가 요청한 태그를 모든 캐시 태그와의 병렬 처리가 필요 • 태그의 길이도 길다. • 직접 사상에 비해 속도가 느리고, 추가 하드웨어 필요
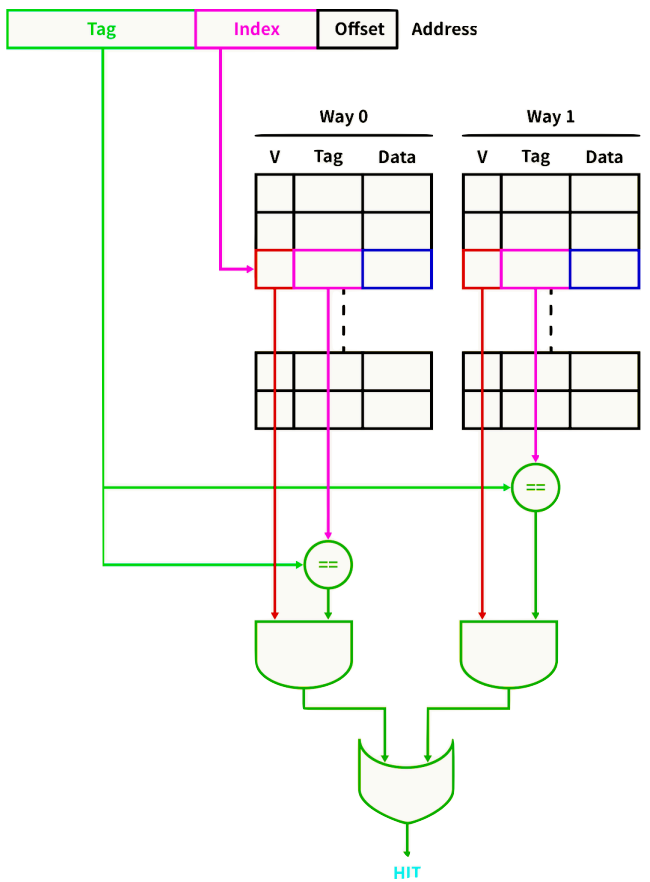
8. Set Associative Cache Organization
- e.g., 2-way set associative 캐시
- 주소의 인덱스를 통해 블록에 접근하는 것은 direct mapped 캐시와 동일
- 다만 2개의 웨이(Way)가 있기 때문에 데이터가 캐싱되어 있는지 확인하려면 하나의 블록만이 아닌 2개의 블록을 모두 확인
- 두 웨이의 결과를 OR 연산하여 최종결과
- 모든 웨이에서 미스가 발생하면 교체 정책에 따라 2개의 블록 중 한 곳에 데이터를 작성
- 히트 레이턴시를 높이는 대신 충돌 가능성을 줄인 것
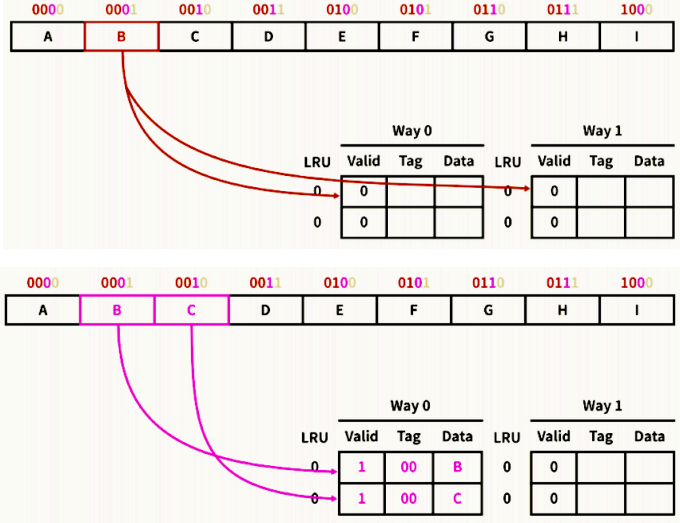
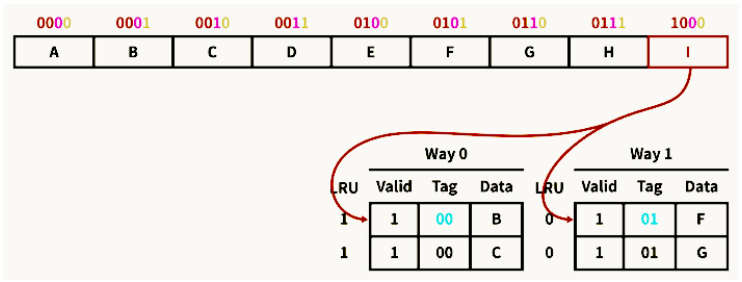
8.1. 예제 1
- 2바이트 캐시 블록으로 구성된 8바이트 2-way 캐시가 있고, 4비트 주소가 주어 질 때,
- [Tag 2][Index 1][Offset 1]
- 메모리 주소 0001을 참조하는 명령이 실행 → [00][0][1] → 미스
- 두 Way중 한 곳에 Index 0 에 대해 캐싱 → 공간지역성에 의해 0010도 함께 캐싱
8.2. 예제 2
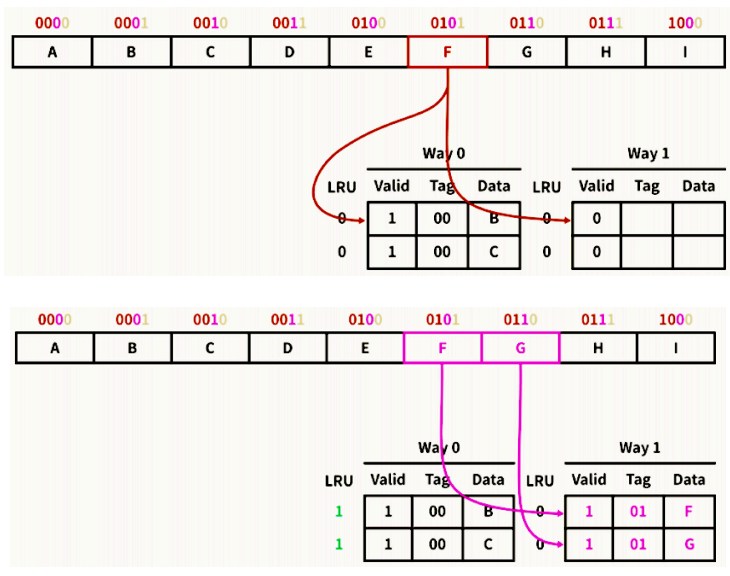
8.3. 예제 3
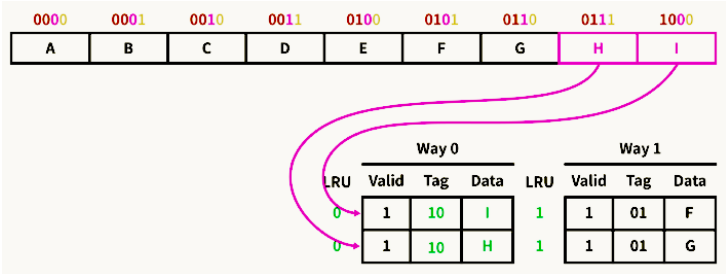
9. Write on cache
- 캐시에 읽는 동작이 아니라 쓰는 동작이 발생하면 어떨까? (Write hit)
- 메모리의 데이터가 업데이트가 되는 것이 아닌 캐시가 업데이트됨 → 동기화 필요
- 동기화에 두가지 방법이 있음
- Write-through
- 캐시에 데이터가 작성될 때마다 메모리의 데이터를 업데이트
- 많은 트래픽이 발생하지만, 메모리와 캐시의 데이터를 동일하게 유지할 수 있음
- Write-back
- 블록이 교체될 때만 메모리의 데이터를 업데이트
- 데이터가 변경됐는지 확인하기 위해 캐시 블록마다 dirty 비트를 추가해야 하며, 데이터가 변경되었다면 1로 바꿔줌
- 이후 해당 블록이 교체될 때 dirty 비트가 1이면 메모리의 데이터를 변경
- 좀 더 주류 방법
이 포스팅은 작성자의 CC BY-NC 4.0 라이선스를 준수합니다.