[OS] 컴퓨터구조: 컴퓨터 시스템과 프로그램의 작동 원리
1. CPU
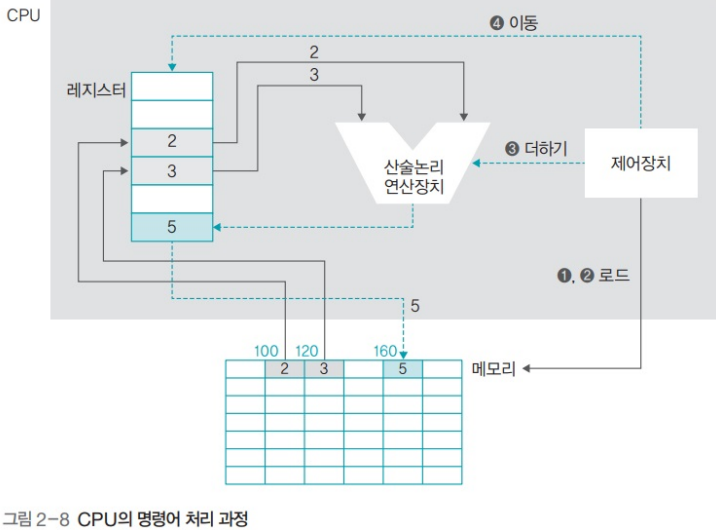
1.1. CPU 구성 요소
- 산술논리 연산장치(ALU, Arithmeti Logic Unit)
- 데이터의 산술 연산 및 AND, OR 같은 논리 연산 수행
- 제어장치 (Control Unit)
- CPU에서 명령어에 따른 작업 지시
- 레지스터 (Register)
- CPU 내 데이터 임시 보관
- 실제 연산/작업 모두 레지스터 거쳐 수행됨
1.2. 명령어 Instruction
- CPU가 해석/실행할 수 있는 기계 명령(machine instruction)
- 컴파일로 만들어진 기계어 코드
- CPU마다 명령 이름, 기계어 코드, 크기, 개수 등이 모두 다름
1
2
3
4
5
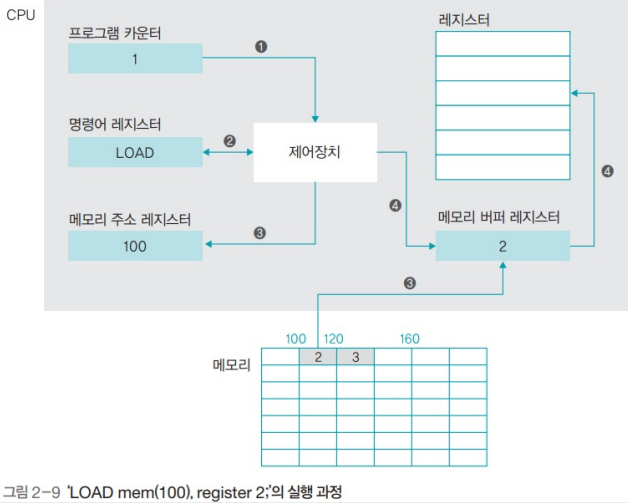
move ecx, 51 ; b9 33 00 00 00 ecx 레지스터에 51 저장
add ax, 8 ; 83 c4 08 ax 레지스터에 8 더하기
push ebp ; 55 ebp 레지스터 값을 스택에 저장
call _printf ; e8 00 00 00 00 _printf 함수 호출
ret 0 ; c3 이 함수를 호출한 곳으로 리턴(0 값과 함께)
이 기계어 코드가 메모리에 적재되어야 하며, CPU가 순차적으로 읽어가며 지정된 동작을 수행한다.
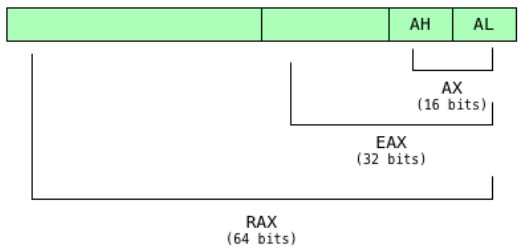
1.3. 레지스터
| 레지스터 | 특징 | |
|---|---|---|
| 사용자 가시 레지스터 | 데이터 레지스터(DR) | CPU가 명령어 처리 시 필요한 일반 데이터를 임시 저장하는 범용 레지스터 |
| 주소 레지스터(AR) | 데이터/명령어가 저장된 메모리 주소 저장 | |
| 사용자 불가시 레지스터 | 프로그램 카운터(PC) | 다음 실행 명령어의 위치 정보(코드 행 번호, 메모리 주소) 저장 |
| 명령어 레지스터(IR) | 현재 실행 중인 명령어 저장 | |
| 메모리 주소 레지스터(MAR) | 메모리 관리자가 접근해야 할 메모리 주소 저장 | |
| 메모리 버퍼 레지스터(MBR) | 메모리 관리자가 메모리에서 가져온 데이터를 임시 저장 | |
| 프로그램 상태 레지스터(PSR) | 연산 결과(양수, 음수, 오버플로 등) 저장 | |
| 레지스터 | 설명 |
|---|---|
| AX, BX, CX, DX | 범용 레지스터 |
| R8-R15 | 범용 레지스터(64 bits only) |
| SI, DI1 | Source/Destination Index |
| BP, SP | Base/Stack 포인터 |
| IP(중요) | Instruction 포인터 |
| Flag 레지스터 | 연산결과에 대한 Flags |
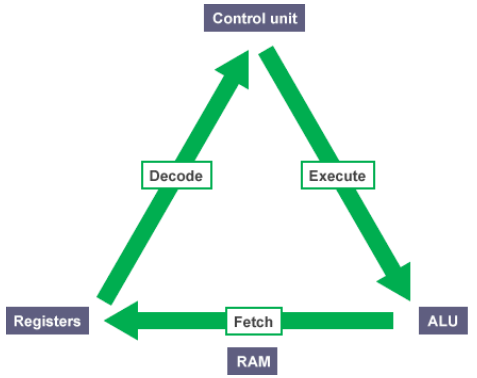
1.4. Instruction Cycle
CPU의 명령어 처리 과정은 Fetch → Decode → Execute의 순서로 진행되는 Instruction Cycle을 거친다.
- Fetch: 기계어 코드를 Program counter(PC)를 통해 순차적으로 읽는다. (RAM)
- Decode: 현재 실행할 명령어가 무엇인지 해석한다. (Control unit)
- Execute: 명령어를 수행한다. (ALU)
2. 메모리
2.1 메모리 보호
현대 OS는 시분할 기법을 사용해 여러 프로그램을 동시에 실행한다. 즉 사용자 영역이 여러 개의 작업공간으로 나뉘어 있는데, 타 프로그램이 다른 프로그램의 메모리 영역을 침범하지 않도록 보호해야 할 필요가 있다. 이것이 메모리 보호가 필요한 이유이다.
메모리가 보호되지 않으면 어떤 작업이 다른 작업의 영역을 침범하여, 프로그램 실행을 방해하거나 데이터에 간섭을 할 수 있다. 그러다 혹시 운영체제 영역을 침범하기라도 하면 매우 곤란해진다.
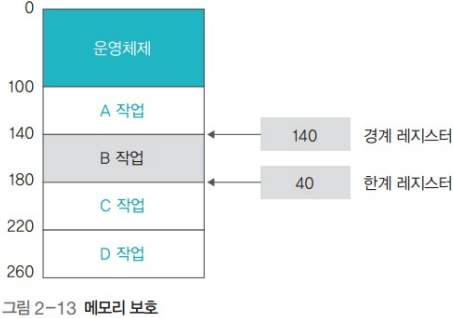
2.2. 메모리 보호 기법: Segmentation
- 작업의 메모리 시작 주소를 경계 레지스터2에 저장, 작업
- 마지막 주소까지의 차이(작업이 차지하는 메모리 크기)를 한계 레지스터2에 저장
- 사용자 작업 진행되는 동안, 이 두 레지스터 주소 범위를 벗어나는지 하드웨어적으로 점검
- 만약 벗어난다면 메모리 오류와 관련된 Interrupt 발생 → OS가 해당 프로그램 강제 종료
→ Segmentation falut
2.3. 부팅
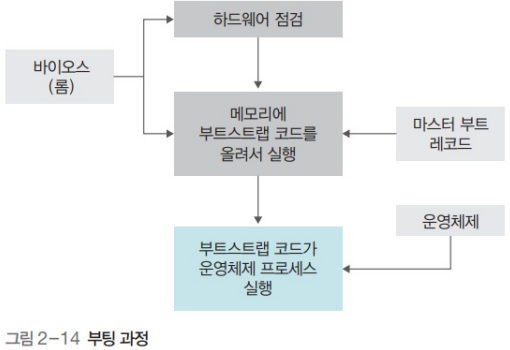
- 부팅: 컴퓨터 켰을 때 OS를 메모리에 올리는 과정
- 부트로더(Boot loader, Bootstrap loader)
- OS를 실행시켜 주기 위한 프로그램 → BIOS/UEFI
- 하드웨어 점검 후 미리 약속된 저장장치의 약속된 위치의 프로그램을 실행시킴
- Master boot record(MBR): 디스크의 첫번째 섹터
- GUID Partition Table (GPT)
3. 폴링과 인터럽트
외부 장치들은 예외 상황(입력 발생, 작업 완료 등)이 발생하면 CPU에게 자신의 상태를 알려준다. CPU는 이러한 상태들을 크게 두 가지 방식으로 처리할 수 있는데, Polling, Interrupt가 그것이다.
- 예외 상황들에 대한 예
- 키보드/마우스 조작
- 네트워크 패킷 수신
- 저장 장치 입력완료
- USB 장치 연결 알림
- 기타 시스템 메시지(segmentation fault 등)
- 등등
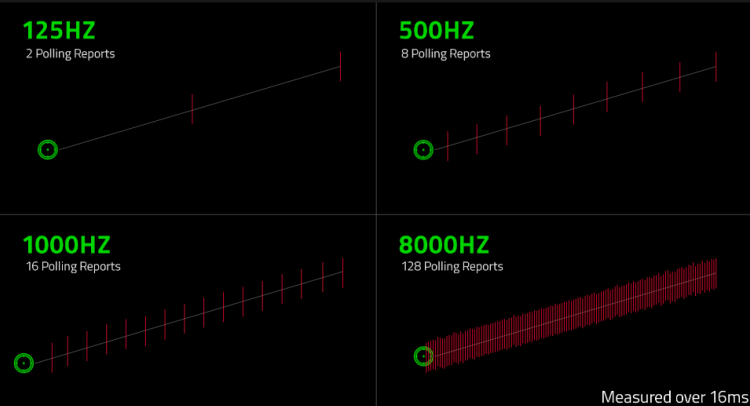
3.1. Polling(Programmed I/O)
- CPU가 입출력장치에서 직접 데이터를 입출력하는 방식
- CPU가 외부 상태를 주기적으로 검사, 요청(Request)이 있으면 처리한다.
- 메시지는 CPU가 poll을 할 때까지 기다려야 한다.
- 폴링 주기(Polling rate)
- 주기가 높을 수록 응답속도 ↑, 실시간성 ↓
- CPU 작업 속도에 영향이 있음
3.2. Interrupt(Interrupt Driven I/O)
- 각 자원들이 능동적으로 자신의 상태변화를 CPU에게 알리는 방식
- CPU는 필요시에만 외부 장치와 통신하며, 남는 시간 동안 다른 작업을 처리한다.
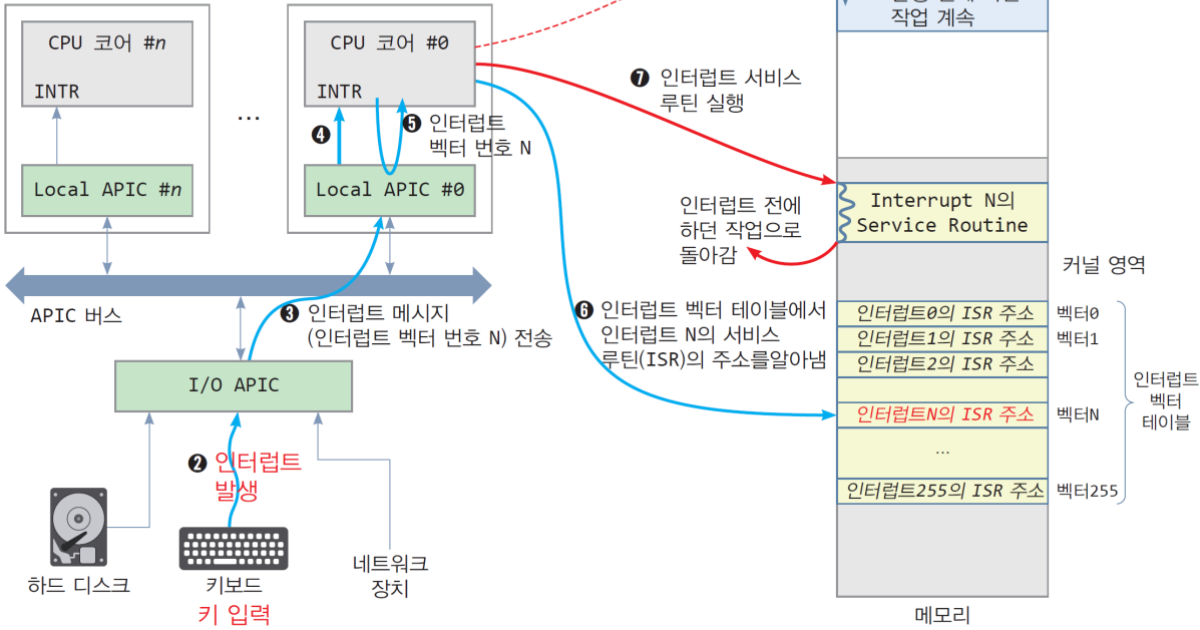
외부 장치가 CPU를 사용해야 할 때, IRQ(Interrupt ReQuest)를 전송한다.
- Interrupt number(ID): 누가 어떤 인터럽트를 발생시킨 건지 구분하기 위한 고윳값
- 현재 CPU의 각종 레지스터와 상태 저장
- 인터럽트 핸들링 위해 ISR(Interrupt Service Routine) 수행
- 다시 원래 수행하던 프로그램으로 돌아가 이어서 처리
이렇듯 인터럽트 방식은 위와 같은 과정으로 CPU의 활용률을 높일 수 있다.3
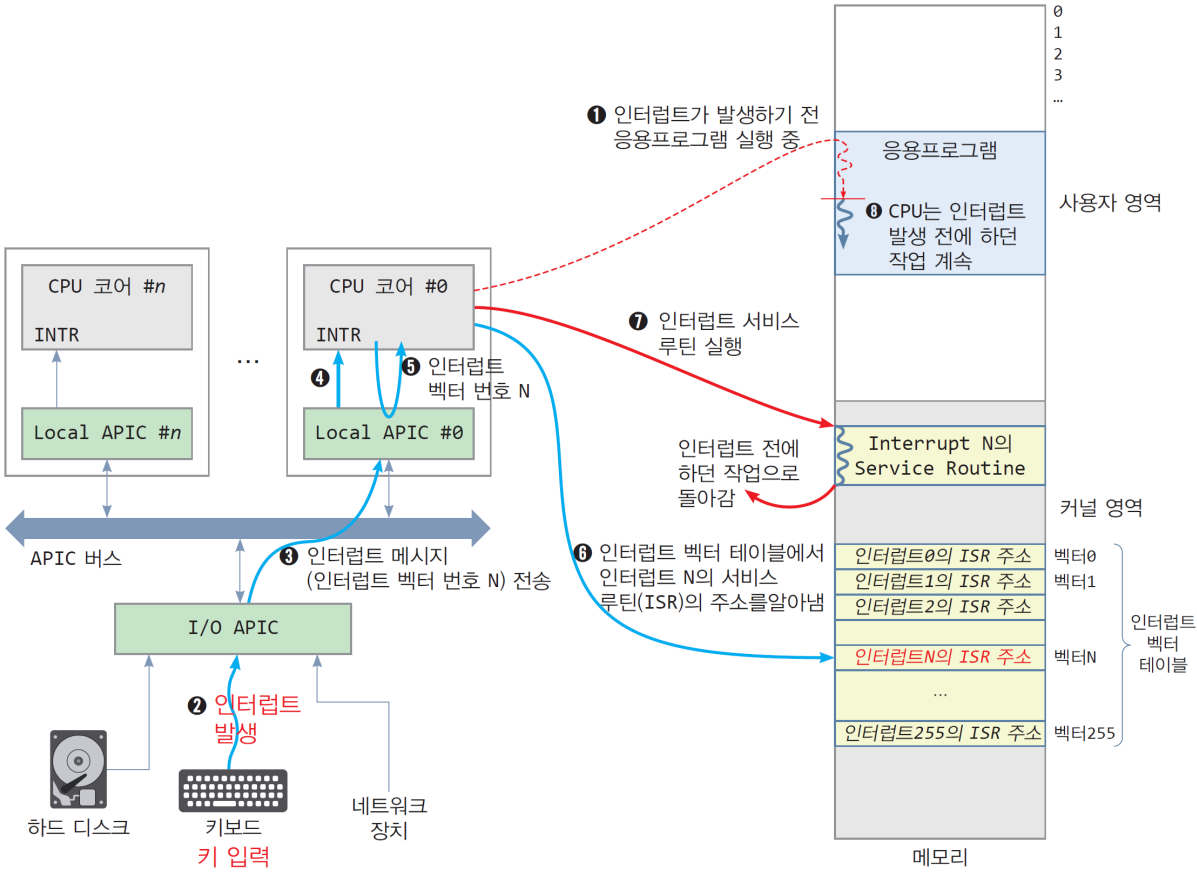 인터럽트 과정
인터럽트 과정
3.2.1. 인터럽트 종류
크게 두가지로 구분된다.
- 하드웨어 인터럽트: CPU 외부의 디스크 컨트롤러/주변장치로부터 요구
- 기계검사 인터럽트: 컴퓨터 자체에 기계적 문제가 발생한 경우
- 외부 인터럽트: 오퍼레이터/타이머에 의해 의도적으로 프로그램 중단된 경우
- 입출력 인터럽트: 입출력 종료/오류에 의해 CPU 기능 요청되는 경우
- 프로그램 검사 인터럽트: 프로그램 실행 중 보호 공간에 접근/불법적 명령 수행 등 문제가 발생한 경우
- 소프트웨어 인터럽트: CPU 내부에서 자신이 실행한 명령어/CPU의 명령 실행에 관련된 모듈이 변화하는 경우
- 프로그램 실행 중 프로그램 상 처리 불가능 오류/이벤트 알리기 위한 경우에 발생
- 트랩(trap), 예외(exception) 이라고 부름
- 예시
- 허용되지 않은 주소 참조
- 0으로 나누기
- 예시
3.3. 폴링 VS 인터럽트
인터럽트는 주로 메시지 빈도가 드물 때 사용되며, 폴링은 메시지 빈도가 짧거나 지속적으로 관찰해야 하는 경우 사용된다. 사실 정답은 없다.
- 폴링을 사용하는 경우
- 마우스 입력4
- 저장장치 입력 완료
- USB 장치 연결 알림
- 인터럽트를 사용하는 경우
- 키보드 입력
- 메모리 참조 위치 초과
- 폴링+인터럽트 같이 쓰는 경우
- 네트워크 패킷 수신
하드웨어의 데이터를 메모리로 가져오려면 어떻게 해야 할까? 폴링과 인터럽트 둘 중 어느 것을 사용해야 하는 것일까?
- 폴링: CPU가 데이터 있는지 확인하고 가져와 처리
- 인터럽트: 장치가 데이터 있다고 말해주면 CPU가 처리
폴링, 인터럽트 모두 데이터의 전송을 CPU가 주관하게 되며, 데이터 이동처리에 시간을 낭비하게 된다. CPU의 개입 없이 하드웨어와 메모리 간 데이터 전송하는 방법이 있을까? 물론, 있다.
4. Direct Memory Access(DMA)
위 문제점의 개선 방안으로 나온 것으로, CPU 개입 없이 메모리와 하드웨어 장치 간 데이터 전송을 가능하게 한다.
- DMA controller, Memory Mapped I/O(MMIO)
- DMA 컨트롤러가 버스를 제어하고, I/O와 메모리 간 전송을 제어한다.
- 메모리에는 입출력 작업을 위한 별도의 공간이 할당되어 있다. (MMIO)
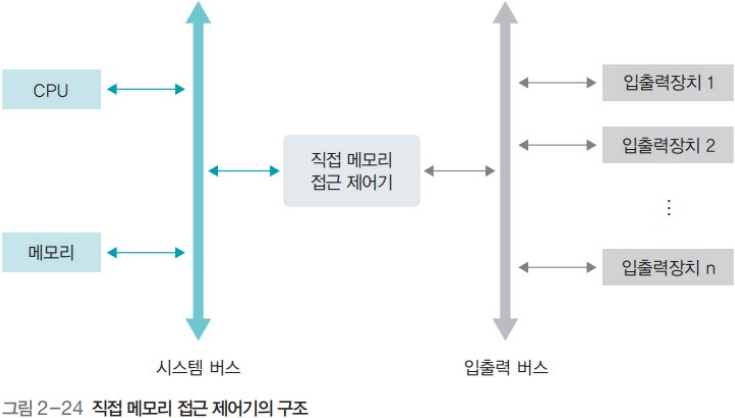

4.1. DMA 동작
- CPU가 할 일
- CPU는 DMA에 데이터의 메모리, 주소, 크기, 대상 장치들을 DMA 컨트롤러에 지시함
- 나머지 데이터 I/O는 DMA 컨트롤러 통해 이뤄짐
- 그 동안 CPU는 다른 작업들을 할 수 있음
- DMA 동작이 끝나면 DMA 컨트롤러는 인터럽트를 발생시킴
4.2. DMA 동작 모드
- 사이클 스틸링 (Cycle Stealing) 모드 - 경쟁적
- DMA 컨트롤러와 CPU가 동시에 BUS를 사용하고자 할 때, 속도 빠른 CPU가 속도 느린 DMA에게 BUS 사용 우선순위를 양보하여 빠른 입출력을 가능하게 하는 방법
- 한번의 DMA 동작 중 한 Word 정도의 데이터 전송 시 사용
- 버스트 모드 (Burst Mode) - 배타적
- 한번의 DMA 동작 중 Block 단위의 데이터 전송시 사용
- 여러 개의 메모리 워드로 구성된 블록이 지속적으로 전송됨
- 고속의 입출력 장치를 대상으로 함
- DMA 인터페이스가 버스 사용권 획득 시 데이터 전송 완료될 때까지 버스 사이클을 독점한다.
- Demand transfer mode
- DMA가 CPU에게 요구한 카운트만큼의 BUS 제어권을 가지는 모드
- 카운트 다 되거나, 중간에 DMA가 반환되면 CPU가 다시 제어권을 가져간다.