[OS] 스케줄링 알고리즘
1. 평가 기준
1.1. 대기 시간(Waiting Time)
- 프로세스가 준비 큐 내에서 대기하는 시간의 총 합
1.2. 반환 시간(Turn-around Time)
- 프로세스가 시작해서 끝날 때까지 걸리는 시간
1.3. 기타 기준
- 응답 시간(Response Time): ‘첫번째’ 응답이 오기 시작할 때까지의 시간
- CPU 사용률(CPU Utilization): 전체 시스템 시간 중 CPU가 작업을 처리하는 시간의 비율
- 처리량(Throughput): CPU가 단위 시간당 처리하는 프로세스의 개수
1.4. 평균 대기시간, 평균 반환시간
- 모든 프로세스의 대기/반환 시간을 합한 뒤 프로세스의 수로 나눈 값
- 일반적으로 이들이 빨라야 좋은 알고리즘이다.
예시

평균 대기시간
(대기 시간) = (작업 시작시간) - (도착 시간)
- P1: $0 - 0 = 0$
- P2: $30 - 3 = 27$
P3: $48 - 6 = 42$
- → 평균 대기시간 $= (0 + 27 + 42) / 3 = 23$
평균 반환시간
(반환 시간) = (작업 종료 시간) - (도착 시간)
- P1: $30 - 0 = 30$
- P2: $48 - 3 = 45$
P3: $57 - 6 = 51$
- → 평균 반환시간 $= (30 + 45 + 51) / 3 = 42$
2. 알고리즘 종류 요약
 알고리즘 종류 요약 (1)
알고리즘 종류 요약 (1)
 알고리즘 종류 요약 (2)
알고리즘 종류 요약 (2)
2.1. FCFS(First Come First Served)
- 비선점 스케줄링
- 도착한 순서대로 스레드를 준비 큐에 넣고 도착한 순서대로 처리
2.2. SJF(Shortest Job First)
- 비선점 스케줄링
- 가장 실행시간 짧은 스레드를 우선으로 처리
2.3. Shortest remaining time first
- 선점 스케줄링
- 지금 실행하는 스레드보다 남은 시간이 더 짧은 스레드가 준비 큐에 들어오면 이를 우선 처리
2.4. Round-robin
- preemptive(선제적)
- 스레드들을 돌아가면서 할당된 시간(타임 슬라이스)만큼 실행
2.5. Priority Scheduling
- 선점/비선점 스케줄링 둘다 구현 가능
- 우선 순위를 기반으로 하는 스케줄링. 가장 높은 순위의 스레드 먼저 실행
2.6. Multilevel queue scheduling
- 선점/비선점 스케줄링 둘다 구현 가능
- 스레드와 큐 모두 n개의 우선순위 레벨로 할당, 스레드는 자신의 레벨과 동일한 큐에 삽입
- 높은 순위의 큐에서 스레드 스케줄링, 높은 순위의 큐가 빌 때 아래 순위의 큐에서 스케줄링
- 스레드는 다른 큐로 이동하지 못함
- 예) background process, Foreground process
2.7. Multilevel feedback queue scheduling
- 선점/비선점 스케줄링 둘다 구현 가능
- 큐만 n개의 우선순위 레벨을 둠. 스레드는 레벨이 없이 동일한 우선순위
- 스레드는 제일 높은 순위의 큐에 진입하고 큐타임슬라이스가 다하면 아래 레벨의 큐로 이동
- 낮은 레벨의 큐에 오래 있으면 높은 레벨의 큐로 이동
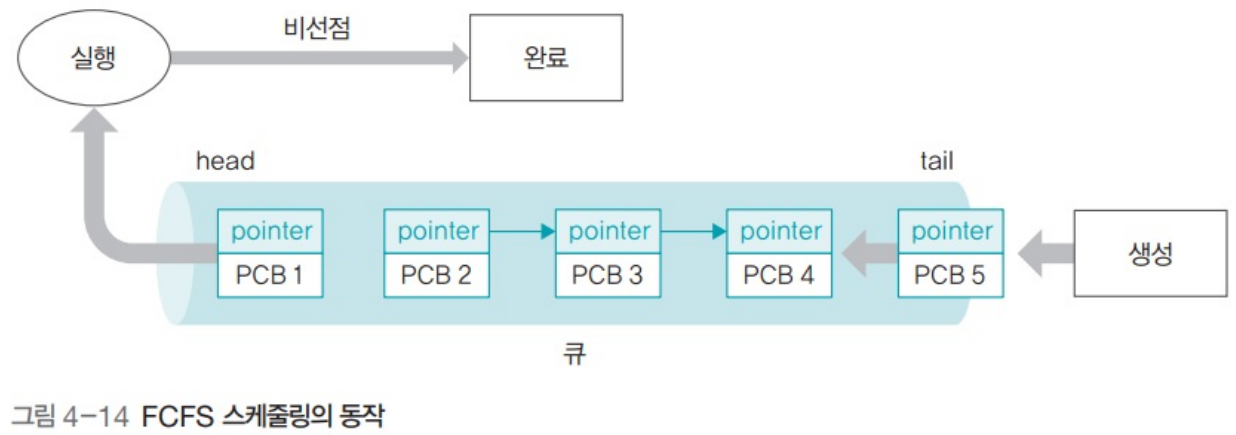
3. FCFS(First Come First Served)
선입선출
- 가장 단순한 형태 (큐 그 자체)
- 멎너 도착한 스레드 먼저 스케줄링
3.1. FCFS 스케줄링의 동작
| 스레드 | 도착 시간 | 실행 시간(ms) |
|---|---|---|
| T1 | 0 | 4 |
| T2 | 1 | 3 |
| T3 | 2 | 1 |
| T4 | 5 | 3 |
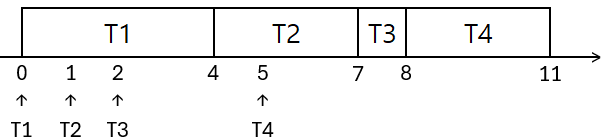 직사각형 속 스레드: 실행중 스레드
직사각형 속 스레드: 실행중 스레드
수직선 밑 스레드: 그 스레드의 도착 시간
 $\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
$\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
큐 맨 왼쪽 스레드: 실행 중 스레드
평균 대기 시간
- T1: $0$
- T2: $4-1=3$
- T3: $7-2=5$
- T4: $8-5=3$
- 평균 대기시간 = $(0+3+5+3)/4=2.75$
평균 반환 시간
- T1: $4$
- T2: $7-1=6$
- T3: $8-2=6$
- T4: $11-5=6$
- 평균 반환시간 = $(4+6+6+6)/4=5.5$
3.2. 요약
4. SJF(Shortest Job First)
- 최단 작업 우선 스케줄링
- 예상 실행 시간이 가장 짧은 스레드를 선택
- 스레드 도착 시, 예상 실행 시간 짧은 순으로 큐에 삽입 후 큐의 맨 앞에 있는 스레드 선택
- 실행중인 스레드보다 더 실행시간 짧은 스레드가 들어와도 현재 스레드는 중단되지 않고 계속 실행됨
4.1. SJF 스케줄링의 동작
Case 1
| 스레드 | 도착 시간 | 실행 시간(ms) |
|---|---|---|
| T1 | 0 | 4 |
| T2 | 1 | 3 |
| T3 | 2 | 1 |
| T4 | 5 | 3 |
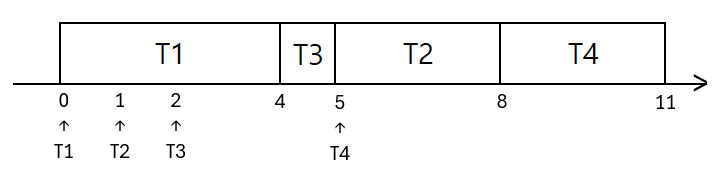 직사각형 속 스레드: 실행중 스레드
직사각형 속 스레드: 실행중 스레드
수직선 밑 스레드: 그 스레드의 도착 시간
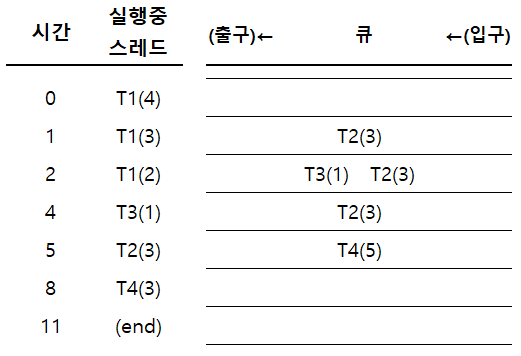 $\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미이다.
$\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미이다.
평균 대기 시간
- T1: $0$
- T2: $5-1=4$
- T3: $4-2=2$
- T4: $8-5=3$
- 평균 대기시간 = $(0+4+2+3)/4=2.25$
평균 반환 시간
- T1: $4$
- T2: $8-1=7$
- T3: $5-2=3$
- T4: $11-5=6$
- 평균 반환시간 = $(4+7+3+6)/4=5$
Case 2
| 스레드 | 도착 시간 | CPU burst 시간 |
|---|---|---|
| T1 | 0 | 14 |
| T2 | 4 | 8 |
| T3 | 8 | 2 |
| T4 | 10 | 8 |
 직사각형 속 스레드: 실행중 스레드
직사각형 속 스레드: 실행중 스레드
수직선 밑 스레드: 그 스레드의 도착 시간
 $\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미이다.
$\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미이다.
평균 대기 시간
- T1: $0$
- T2: $16-4=12$
- T3: $14-8=6$
- T4: $24-10=14$
- 평균 대기시간 = $(0+12+6+14)/4=8$
평균 반환 시간
- T1: $14$
- T2: $24-4=20$
- T3: $16-8=8$
- T4: $32-10=22$
- 평균 반환시간 = $(14+20+8+22)/4=16$
4.2. 요약
| 평가 항목 | 내용 |
|---|---|
| 스케줄링 파라미터 | 스레드별 예상 실행 시간(남은 실행 시간) |
| 스케줄링 타입 | 비선점 스케줄링3 |
| 스레드 우선순위 | 없음 |
| 기아 | 발생 가능4 |
| 성능 이슈 | 짧은 스레드 먼저 실행 → 평균 대기시간 최소화 |
4.3. 문제점
- 실행 시간의 예측이 불가능하기 때문에 현실에서 거의 사용되지 않음
5. SRTF(Shortest Remaining Time First)
- 가장 짧은 실행시간을 우선하는 스케줄링
- SJF 스케줄링의 선점 방식 버전이라 할 수 있음
- 실행중인 스레드보다 더 실행시간 짧은 스레드가 들어오면 현재 스레드를 중단하고 그 스레드를 실행
Case 1
| 스레드 | 도착 시간 | 실행 시간(ms) |
|---|---|---|
| T1 | 0 | 4 |
| T2 | 1 | 3 |
| T3 | 2 | 1 |
| T4 | 5 | 3 |
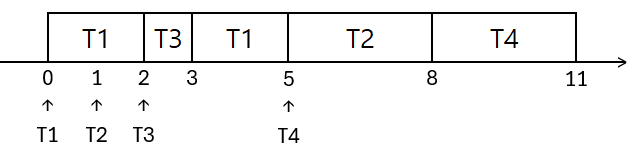 직사각형 속 스레드: 실행중 스레드
직사각형 속 스레드: 실행중 스레드
수직선 밑 스레드: 그 스레드의 도착 시간
 $\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
$\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
큐 맨 왼쪽 스레드: 실행 중 스레드
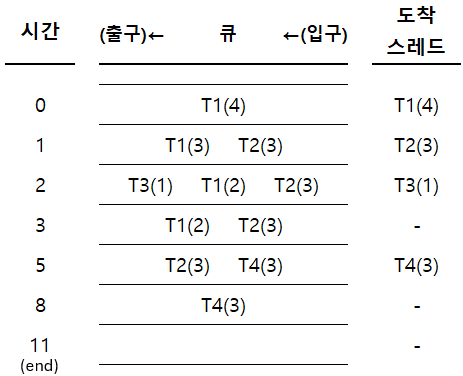
평균 대기 시간
- T1: $(0-0) + (3-2) = 1$
- T2: $(5-1) = 4$
- T3: $(2-2) = 0$
- T4: $(8-5)=3$
- 평균 대기시간 = $(1+4+0+3)/4=2$
평균 반환 시간
- T1: $5-0=5$
- T2: $8-1=7$
- T3: $3-2=1$
- T4: $11-5=6$
- 평균 반환시간 = $(5+7+1+6)/4=4.75$
Case 2
| 스레드 | 도착 시간 | CPU burst 시간 |
|---|---|---|
| T1 | 0 | 14 |
| T2 | 4 | 8 |
| T3 | 8 | 2 |
| T4 | 10 | 8 |
 직사각형 속 스레드: 실행중 스레드
직사각형 속 스레드: 실행중 스레드
수직선 밑 스레드: 그 스레드의 도착 시간
 $\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
$\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
큐 맨 왼쪽 스레드: 실행 중 스레드
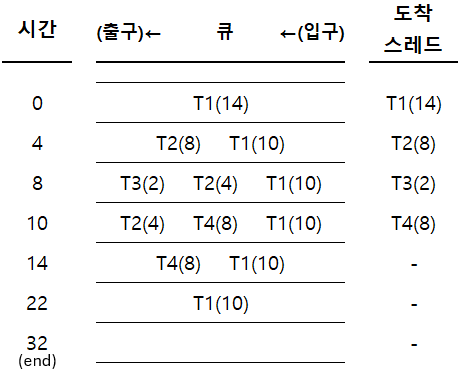
평균 대기 시간
- T1: $(0-0) + (22-4) = 18$
- T2: $(4-4) + (10-8) = 2$
- T3: $(8-8) = 0$
- T4: $(14-10) = 4$
- 평균 대기시간 = $(18+2+0+4)/4=6$
평균 반환 시간
- T1: $32-0=32$
- T2: $14-4=10$
- T3: $10-8=2$
- T4: $22-10=12$
- 평균 반환시간 = $(32+10+2+12)/4=14$
5.1. 요약
| 평가 항목 | 내용 |
|---|---|
| 스케줄링 파라미터 | 스레드별 예상 실행 시간(남은 실행 시간) |
| 스케줄링 타입 | 선점 스케줄링 |
| 기아 | 발생 가능5 |
6. Round-robin(RR, 라운드 로빈)
- 스레드에게 공평한 실행 기회 주기 위해 큐에 대기 중 스레드들을 타임 슬라이스 주기로 돌아가면서 선택
- 도착 순서대로 스레드들을 큐에 삽입
- 타임 슬라이스 지나면 큐 끝으로 이동
6.1. Round-robin의 동작
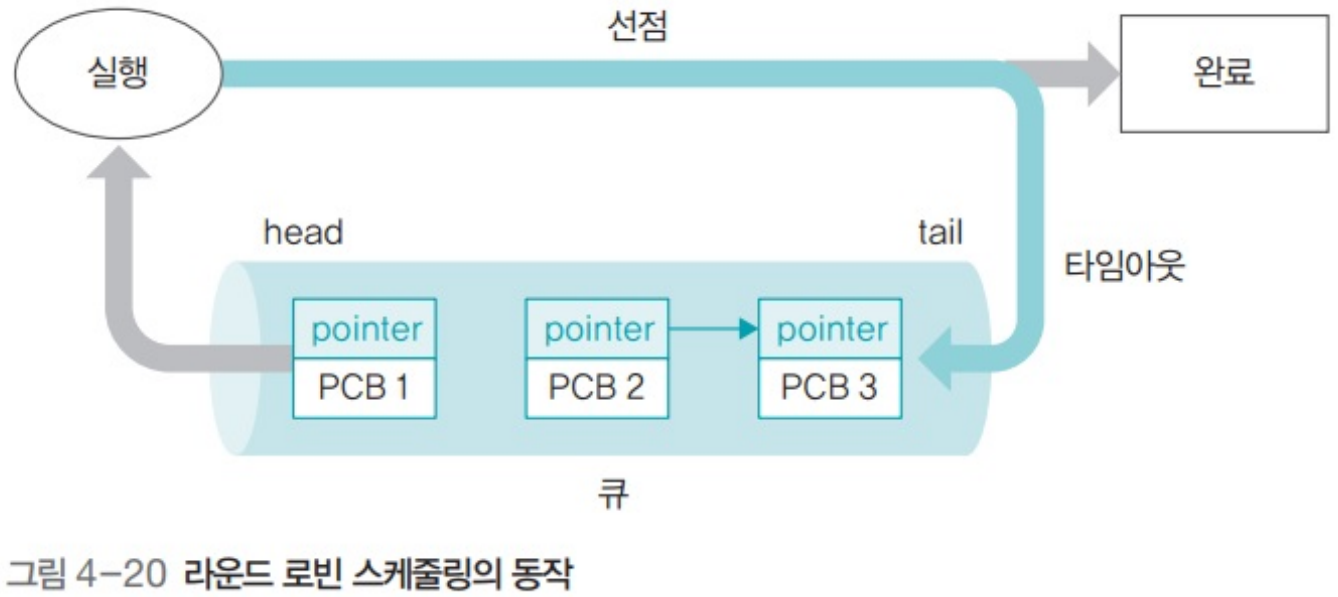
Case 1
| 스레드 | 도착 시간 | 실행 시간(ms) |
|---|---|---|
| T1 | 0 | 4 |
| T2 | 1 | 3 |
| T3 | 2 | 1 |
| T4 | 5 | 3 |
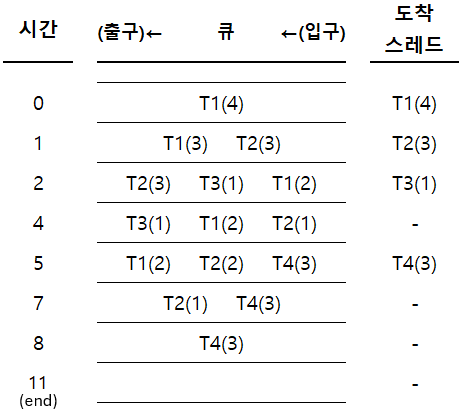
1) Time slice가 2ms인 경우
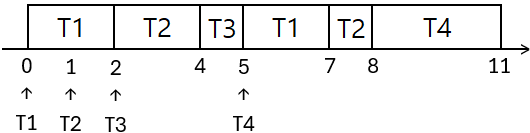 직사각형 속 스레드: 실행중 스레드
직사각형 속 스레드: 실행중 스레드
수직선 밑 스레드: 그 스레드의 도착 시간
 $\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
$\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
큐 맨 왼쪽 스레드: 실행 중 스레드
평균 대기 시간
- T1: $(0-0) + (5-2) = 3$
- T2: $(2-1) + (7-4) = 4$
- T3: $(4-2) = 2$
- T4: $(8-5) = 3$
- 평균 대기시간 = $(3+4+2+3)/4=3$
평균 반환 시간
- T1: $7-0=7$
- T2: $8-1=7$
- T3: $5-2=3$
- T4: $11-6=6$
- 평균 반환시간 = $(7+7+3+6)/4=5.75$
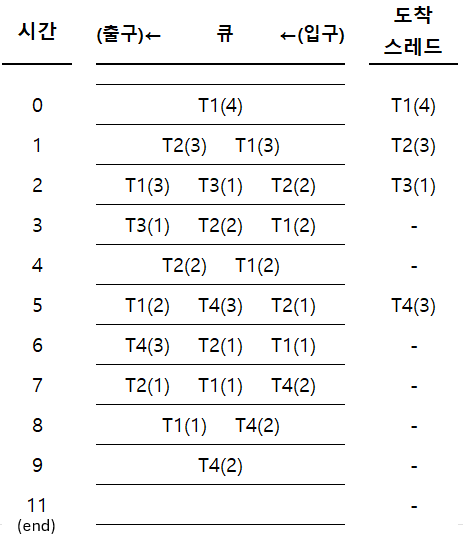
2) Time slice가 1ms인 경우
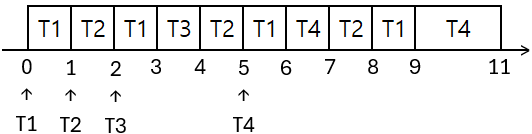 직사각형 속 스레드: 실행중 스레드
직사각형 속 스레드: 실행중 스레드
수직선 밑 스레드: 그 스레드의 도착 시간
 $\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
$\mathrm{T}n(k)$ = $n$번 스레드의 남은 실행 시간은 $k$라는 의미
큐 맨 왼쪽 스레드: 실행 중 스레드
평균 대기 시간
- T1: $0+1+2+2 = 5$
- T2: $0+2+2 = 4$
- T3: $1$
- T4: $1+2 = 3$
- 평균 대기시간 = $(5+4+1+3)/4=3.25$
평균 반환 시간
- T1: $9-0=9$
- T2: $8-1=7$
- T3: $4-2=2$
- T4: $11-5=6$
- 평균 반환시간 = $(9+7+2+6)/4=6$
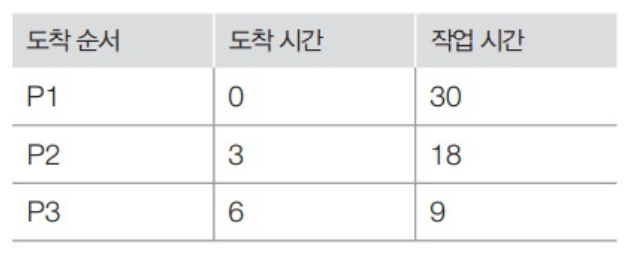
Case 2
- Time slice가 10ms인 경우
| 도착 순서 | 도착 시간 | 작업 시간 |
|---|---|---|
| P1 | 0 | 30 |
| P2 | 3 | 18 |
| P3 | 6 | 9 |
 직사각형 속 프로세스: 실행중 프로세스
직사각형 속 프로세스: 실행중 프로세스
수직선 밑 프로세스: 그 프로세스의 도착 시간
 $\mathrm{T}n(k)$ = $n$번 프로세스의 남은 실행 시간은 $k$라는 의미
$\mathrm{T}n(k)$ = $n$번 프로세스의 남은 실행 시간은 $k$라는 의미
큐 맨 왼쪽 프로세스: 실행 중 프로세스
평균 대기 시간
- P1: $0 + (29-10) + (47-39) = 27$
- P2: $(10-3) + (39-20) = 26$
- P3: $20-6=14$
- 평균 대기시간 = $(27+26+14)/3=22.33$
평균 반환 시간
- P1: $57-0=57$
- P2: $47-3=44$
- P3: $29-6=23$
- 평균 반환시간 = $(57+44+23)/4=41.33$
6.2. 요약
| 평가 항목 | 내용 |
|---|---|
| 스케줄링 파라미터 | 타임 슬라이스 |
| 스케줄링 타입 | 선점 스케줄링 |
| 스레드 우선순위 | 없음 |
| 기아 | 없음6 |

6.3. 성능 이슈
- 공평하고, 기아 현상 없고, 구현 쉬움
- 잦은 스케줄링으로 전체 스케줄링 오버헤드 ↑
- 특히 타임슬라이스 작은 경우 더 커짐
- 균형된 처리율
- 타임 슬라이스 크기 ↑: FCFS에 가까움
- 타임 슬라이스 크기 ↓: SJF/SRTF에 가까움
- 늦게 도착한 짧은 프로세스: FCFS보다 빨리 완료됨
- 긴 프로세스: SJF보다 빨리 완료됨
7. 우선순위(Priority)
- 우선순위에 따라 스레드를 실행
- 가장 높은 우선순위의 스레드 선택
- 현재 스레드가 종료되거나 더 높은 순위의 스레드가 도착할 때, 가장 높은 순위의 스레드 선택
- 도착하는 스레드는 우선순위 순으로 큐에 삽입된다.
7.1. 고정 우선순위 알고리즘
- 한 번 우선순위를 부여받으면 종료때까지 우선순위 고정
- 단순히 구현 가능하지만, 시시각각 변하는 시스템 상황 반형 X → 효율성↓
7.2. 변동 우선순위 알고리즘
- 일정 시간마다 우선순위 변하여 일정시간마다 우선순위 새로 계산/반영
- 복잡하지만, 시스템 상황 반영해 효율적인 운영 가능
예시
| 도착 순서 | 도착 시간 | 작업 시간 | 우선 순위 |
|---|---|---|---|
| P1 | 0 | 30 | 3 |
| P2 | 3 | 18 | 2 |
| P3 | 6 | 9 | 1 |
비선점인 경우
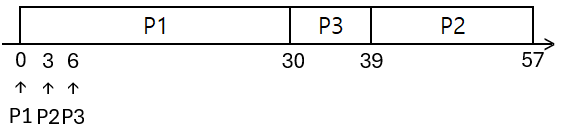 직사각형 속 프로세스: 실행중 프로세스
직사각형 속 프로세스: 실행중 프로세스
수직선 밑 프로세스: 그 프로세스 도착 시간
 $\mathrm{T}n(k,p)$ = $n$번 프로세스 남은 실행 시간은 $k$이고, 우선순위는 $p$라는 의미
$\mathrm{T}n(k,p)$ = $n$번 프로세스 남은 실행 시간은 $k$이고, 우선순위는 $p$라는 의미
평균 대기 시간
- P1: $0$
- P2: $(39-3) = 36$
- P3: $(30-6) = 24$
- 평균 대기시간 = $(0 + 36 + 24)/3 = 20$
평균 반환 시간
- P1: $0$
- P2: $(57-3) = 54$
- P3: $(39-6) = 33$
- 평균 반환시간 = $(0 + 54 + 33)/3 = 29$
선점인 경우
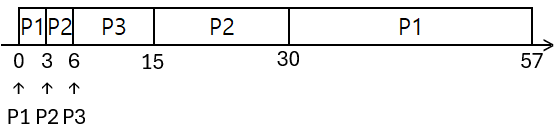 직사각형 속 프로세스: 실행중 프로세스
직사각형 속 프로세스: 실행중 프로세스
수직선 밑 프로세스: 그 프로세스 도착 시간
 $\mathrm{T}n(k,p)$ = $n$번 프로세스 남은 실행 시간은 $k$이고, 우선순위는 $p$라는 의미
$\mathrm{T}n(k,p)$ = $n$번 프로세스 남은 실행 시간은 $k$이고, 우선순위는 $p$라는 의미
큐 맨 왼쪽 스레드: 실행 중 스레드
평균 대기 시간
- P1: $(30-3) = 27$
- P2: $(15-6) = 9$
- P3: $0$
- 평균 대기시간 = $(27 + 9 + 0)/3 = 12$
평균 반환 시간
- P1: $(57-0) = 57$
- P2: $(30-3) = 27$
- P3: $(15-6) = 9$
- 평균 반환시간 = $(57+27+9)/3= 31$
7.3. 요약
| 평가 항목 | 내용 |
|---|---|
| 스케줄링 파라미터 | 스레드 별 고정 우선순위 |
| 스케줄링 타입 | 선점/비선점 스케줄링 |
| 스레드 우선순위 | 있음 |
| 기아 | 발생 가능 |
| 성능 이슈 | 높은 우선순위일수록 대기/응답시간 짧음 Real-time OS에서 유리 |
- 스케줄링 타입
- 선점 스케줄링인 경우: 더 높은 스레드가 도착할 때 현제 스레드 강제 중단 후 스케줄링
- 비선점 스케줄링인 경우: 현재 실행 중인 스레드가 종료될 때 비로소 스케줄링
- 기아
- 지속적으로 높위 스레드 도착하는 경우, 언제 실행 기회 얻을 지 예상 불가
- 큐 대기시간에 비례, 일시적으로 우선순위 높이는 에이징 방법으로 해결 가능
8. HRN 스케줄링(Highest Response ratio Next)
- 기아현상을 완화하기 위해 만들어진 알고리즘
- SJF의 변형
- 서비스 받기 위해 기다린 시간과 CPU 사용시간 고려해 스케줄링 하는 방식
- 반드시 비선점이어야 함!
- 선점인 경우 매 클럭마다 우선순위가 달라지므로, 매 클럭마다 문맥 교환이 일어날 수 있음!
8.1. 예시
Case 1
| 작업 | 대기 시간 | 서비스 시간 | 우선순위 |
|---|---|---|---|
| A | 5 | 20 | $(5 + 20)/20 = 1.25$ |
| B | 40 | 20 | $1 + (40/20) = 3$ |
| C | 15 | 45 | $1 + (15/45) = 1.333$ |
| D | 20 | 20 | $1 + (20/20) = 2$ |
- 정적 우선순위였다면 B - D - C - A 순으로 실행이 될 것임
- 동적 우선순위였다면
- B가 모두 실행되면 나머지 작업의 대기시간이 모두 +20이 될 것임
- 그러면 우선순위가 달라지므로 실행 순서가 달라질 수 있음
Case 2
| 도착 순서 | 도착 시간 | 작업 시간 | P1 끝난 시점($t=30$)의 우선순위 |
|---|---|---|---|
| P1 | 0 | 30 | 고려 X |
| P2 | 3 | 18 | $1 + (27/18) = 2.5$ (대기시간 27) |
| P3 | 6 | 9 | $1 + (24/9) = 3.66$ (대기시간 24) |
- 따라서 $t=30$일 때 P3이 우선 실행되게 된다.
평균 대기 시간
- P1: $0$
- P2: $27$
- P3: $24$
- 평균 대기시간 = $(0 + 27 + 24)/3 = 17$
8.2. 요약
9. MLQ(Multi-level Queue)
- 스레드를 n개의 우선순위 레벨로 구분한 후, 우선순위 레벨 높은 스레드들을 우선적으로 처리함
- 고정된 n개의 큐 사용, 각 큐에 고정 우선순위 할당
- 스레드들의 우선순위도 n개의 레벨로 분류
- 각 큐는 나름대로의 기법으로 스케줄링
- 스레드 도착 시 우선순위에 따라 해당 레벨 큐에 삽입
- 다른 큐로 이동할 수 없음
- 가장 높은 순위 큐가 빌 때, 그 다음 순위의 큐에서 스케줄링함
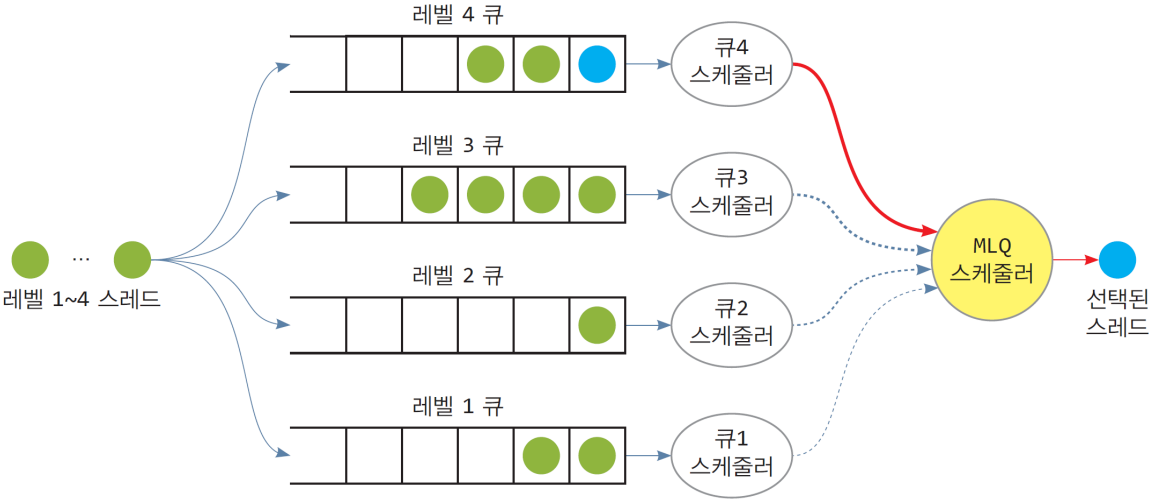 MLQ 알고리즘의 예시
MLQ 알고리즘의 예시
10. MLFQ(Multi-level Feedback Queue)
- 기아를 없애기 위해 여러 레벨의 큐 사이 간 스레드 이동이 가능하도록 설계됨
- 고정된 n개의 큐 사용, 큐마다 서로 다른 레벨 스케줄링 알고리즘
- 큐마다 스레드가 머무를 수 있는 큐 타임슬라이스가 있음
- 낮은 레벨 큐일수록 더 긴 타임 슬라이스
- 스레드는 도착 시 최상위 레벨의 큐에 삽입
- 가장 높은 레벨의 큐에서 스레드 선택. 비어 있는 경우 그 아래의 큐에서 스레드 선택
- 스레드의 CPU-burst가 큐 타임 슬라이스를 초과하면 강제로 아래 큐로 이동시킴
- 스레드가 자발적으로 중단한 경우, 현재 큐 끝에 삽입
- 스레드가 I/O로 실행이 중단된 경우, I/O가 끝나면 동일한 레벨 큐 끝에 삽입
- 큐에 있는 시간이 오래되면 기아를 막기 위해 하나 위 레벨 큐로 이동
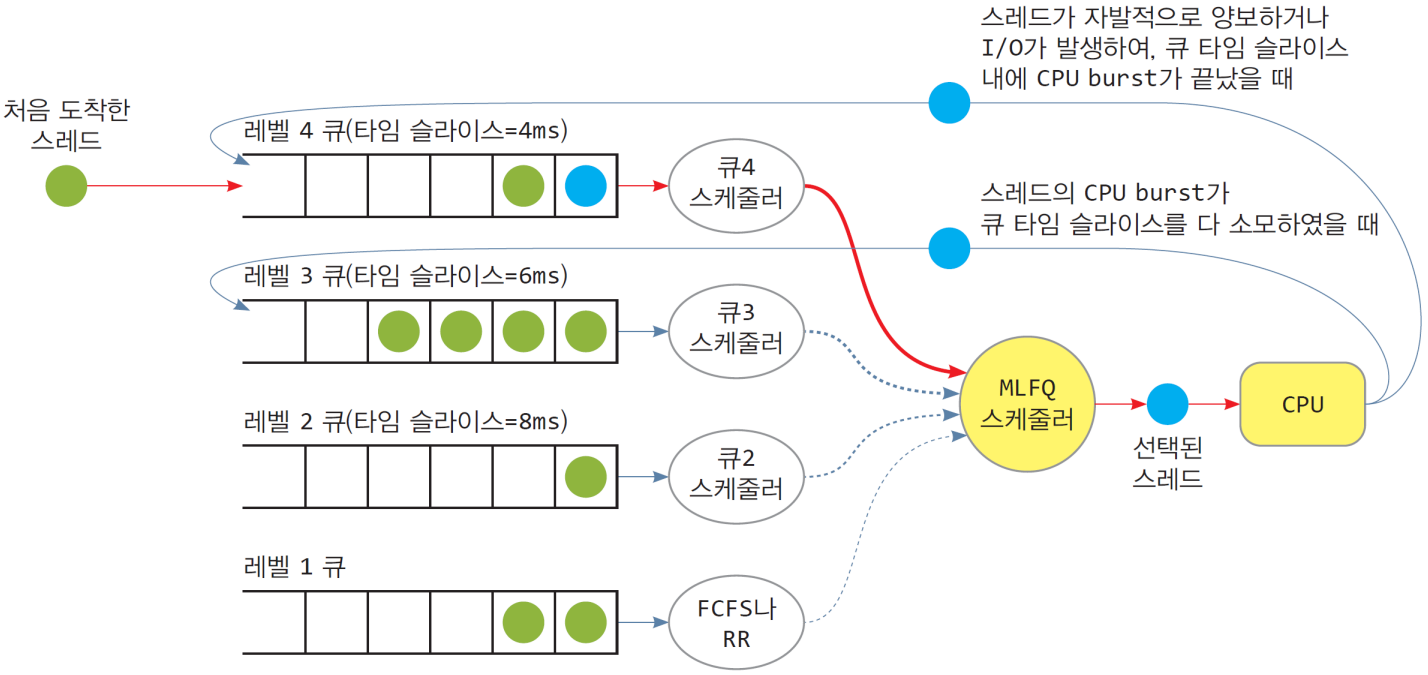 MLFQ 알고리즘의 예시
MLFQ 알고리즘의 예시
예시
- 3개의 레벨 큐
- 3개의 스레드
 MLFQ 알고리즘의 예시
MLFQ 알고리즘의 예시
- 평균 대기 시간: $(5+13+13)/3 = 10.3$
10.1. 요약
11. 참고
- 각 스케줄링 알고리즘은 서로 섞여서 사용될 수 있음
- RR + SJF
- MLQ + FCFS
- MLQ + RR
- …
- 꼭 Queue만 사용하는 것은 아님
- 리눅스 CFS(Completely Fair Scheduler): Red-black tree 구조 활용
- 우선순위마다 다른 스케줄링dl 사용되기도 함
- 리눅스의 경우(숫자가 낮을 수록 높은 우선순위)
- Priority 0-99: Real-time process, static priority (RR 사용)
- Priority 100-139: Ordinary process, dynaic priority (CFS 사용)
- 리눅스의 경우(숫자가 낮을 수록 높은 우선순위)
12. 멀티코어 CPU 스케줄링
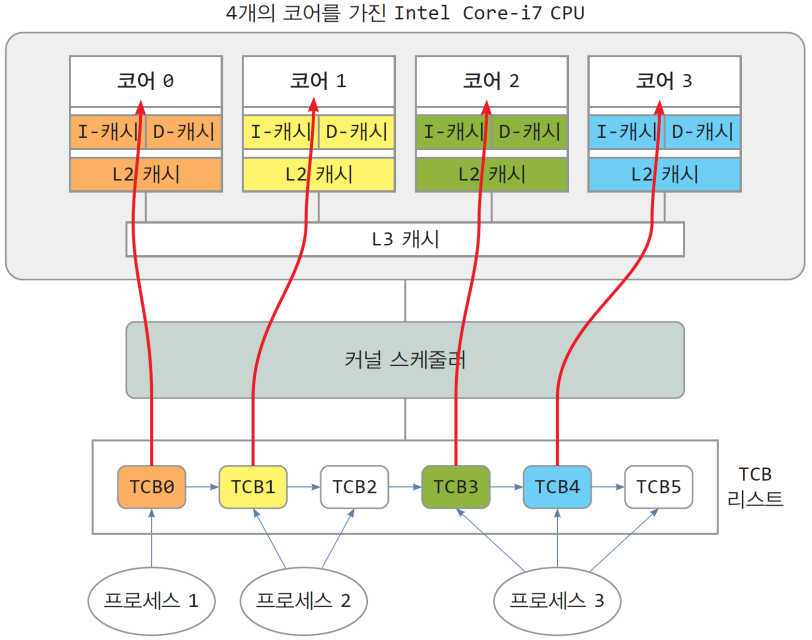 멀티코어 CPU 스케줄링의 예
멀티코어 CPU 스케줄링의 예
12.1. 문제점
- 스케줄링을 통해 프로세스는 지정된 순서에 따라 CPU를 들락날락함
- 그런데 멀티코어에서는 스케줄링이 여러 CPU에 걸쳐 발생하게 될 수 있음
- 서로 다른 코어에 걸쳐서 Context Switching이 발생한다면?
- C1, 컨텍스트 스위칭 오버헤드 증가 문제
- 이전에 실행된 적 없는 코어에 스레드가 배치될 때
- ex) Core1 → Core3
- 캐시에 새로운 스레드의 코드와 데이터로 채워지는 긴 경과 시간
- 이전에 실행된 적 없는 코어에 스레드가 배치될 때
- C2, 코어별 부하 불균형 문제
- 스레드를 무작위로 코어에 할당시, 코어마다 처리할 스레드 수의 불균형 발생
- ex) P1 → Core1, P2 → Core1, P3 -> Core1, P4 → Core1, …
- Core2, Core3은?
- ex) P1 → Core1, P2 → Core1, P3 -> Core1, P4 → Core1, …
- 스레드를 무작위로 코어에 할당시, 코어마다 처리할 스레드 수의 불균형 발생
12.2. 해결책
12.2.1 코어간 Context switching 문제
CPU 친화성(CPU affinity) 부여로 해결한다.
- a.k.a., 코어 친화성(Core affinity), CPU 피닝(pinning), 캐시 친화성
- 스레드를 동일한 코어에서만 실행하도록 스케줄링
코어 당 스레드 큐 사용
- 윈도우 예시
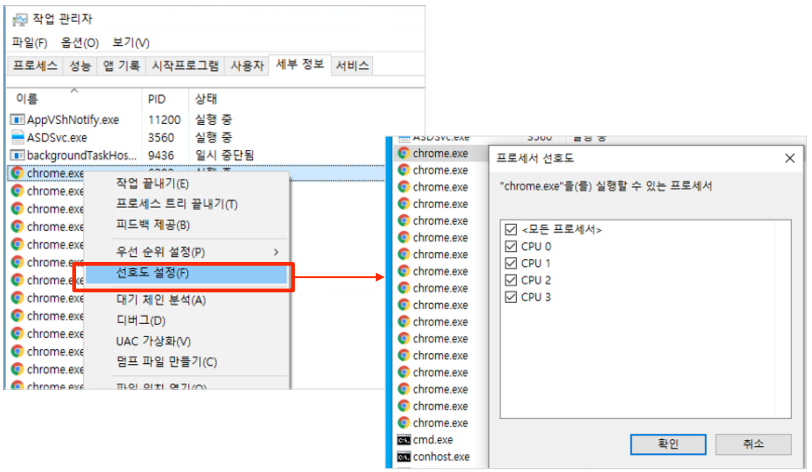 윈도우에서의 코어 친화성 설정
윈도우에서의 코어 친화성 설정
- 리눅스 예시
taskset -c <논리 CPU번호> <명령어>- 확인:
sar -P 0 1 1
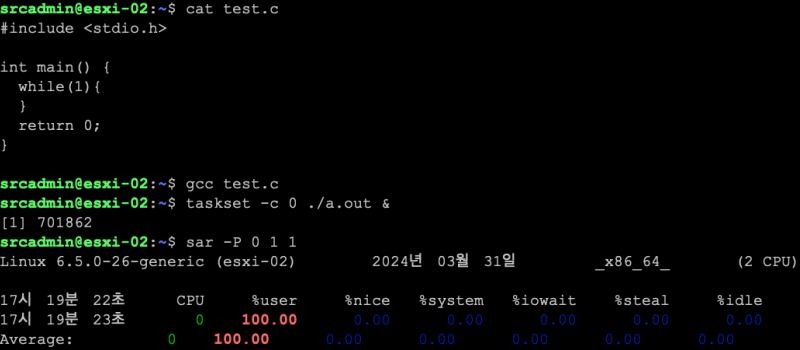 리눅스에서의 코어 친화성 설정
리눅스에서의 코어 친화성 설정
12.2.2 코어별 부하 불균형 문제
부하 균등화 기법으로 해결한다.
- 코어 사용량 감시 스레드가 작업을 재할당(migration)하여 부하 분산
- Push migration
- 짧거나 빈 큐 가진 코어에 다른 큐 스레드를 옮겨놓는 기법
- Pull migration
- 코어가 처리할 스레드가 없게 되면, 다른 코어의 스레드 큐에서 자신이 큐에 가져와 실행시키는 기법
13. 생각해볼 거리
- 하나의 프로세스에 일어나는 작업을 여러 코어/스레드에 걸쳐서 하려면?
- 만약 공유데이터에 두 함수가 아무 생각 없이 임의의 순서로 접근하면
- 공유데이터가 훼손되는 문제 발생
- 공유데이터에 다수의 스레드가 접근시에는 서로 합을 맞추는 것이 필요함
- 그래서 다음시간에 배우는 것 → 동기화(Synchronazation)
각주
단 한 스레드가 오류로 인해 무한 루프가 발생(실행시간 → $\inf$)하면 뒤 스레드의 기아 발생 ↩
긴 스레드가 CPU 오래 사용 시, 늦게 도착한 스레드는 오래 대기 ↩
하지만 선점도 가능한데, 이 경우는 SRTF(Shortest Remaining Time First) 알고리즘이 된다. ↩
지속적으로 짧은 스레드 도착 시, 긴 스레드는 언제 실행 기회 얻을 지 예측 불가능하다. ↩
SJF와 마찬가지로 짧은 스레드가 계속 들어오면 기아 발생이 가능함 ↩
스레드 우선순위가 없고, 타임 슬라이스가 정해져 있으므로 일정 시간 후에 스레드는 반드시 실행된다. ↩