[OS] 스레드와 스레드 주소 공간
1. 프로세스의 문제점
프로세스는 여러 프로그램을 동시에 실행시키기 위해 고안된 개념이지만, 이것을 그대로 사용하기에는 다음과 같은 문제점이 있다.
1.1. 프로세스 생성 오버헤드가 크다.
- 메모리 할당 →
fork()→ PCB → Page(segment) 매핑 테이블 → … 으로 이뤄지는 복잡한 과정을 거쳐야 한다.
1.2. 프로세스 간 통신이 어렵다.
- 프로세스들은 완전히 독립적인 주소 공간을 가지고 있다.
- 서로 다른 프로세스끼리는 간섭이 불가능하다.
- 프로세스간의 통신을 위해 별도의 방법이 필요하다.
- Shared memory
- socket
- message queue 등
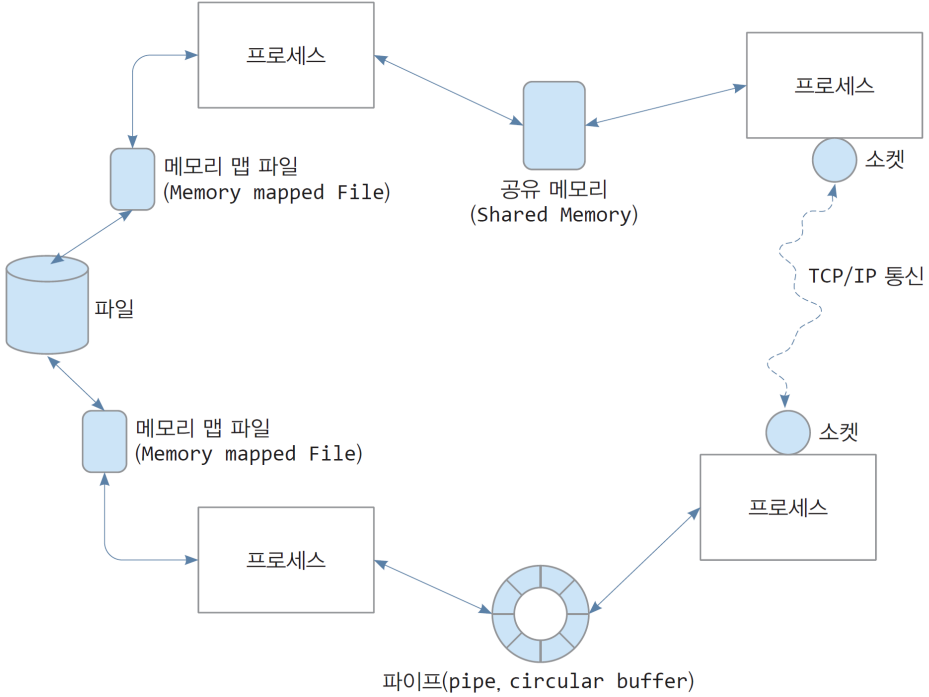 (참고) 프로세스간 다양한 통신 방법
(참고) 프로세스간 다양한 통신 방법
이와 같은 문제점들로 인해 하나의 작업을 여러 모듈 단위로 쪼개서 작업하기가 어려워진다.
예를 들어 미디어 플레이어의 경우, 아래 기능들이 동시에1 이뤄져야 한다.
- 영상 처리
- 소리 처리
- 자막 처리
- 기타 등등..
각 기능들이 프로세스 기반 멀티테스킹이라면, context switching 하기에는 하나하나가 너무 무거우며, 따라서 시분할 사이 시간이 길어질 수밖에 없다!
1.3. 스레드: 프로세스의 대안
위와 같은 프로세스의 문제점을 해결하기 위해 고안된 것이 바로 스레드이다.
- 스레드란?
- 프로세스보다 ‘더 작은’ 실행 단위
- 현대 OS가 작업을 ‘스케줄링’하는 단위
- CPU 스케줄러가 CPU에 작업을 전달하는 단위2
- 스레드 사용으로 인한 효과
- 프로세스 생성/소멸에 따른 오버헤드를 감소
- 빠른 Context switching
- 손쉬운 통신
- 스레드는 또한 lightweight process 라고도 불림
- 참고
- OS의 작업 단위: Process
- CPU의 작업 단위: Thread
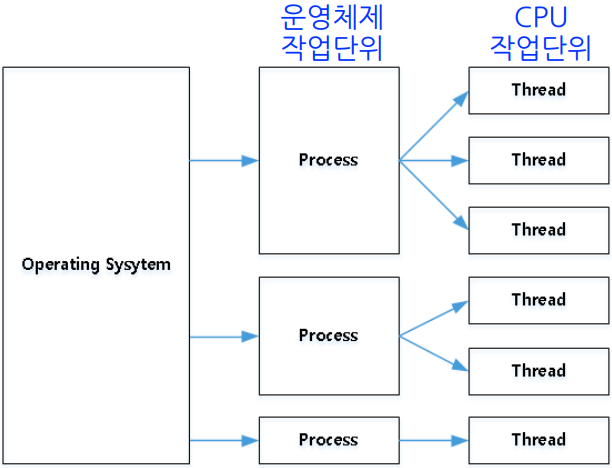 작업 단위의 구분
작업 단위의 구분
2. 프로세스: 스레드들의 컨테이너
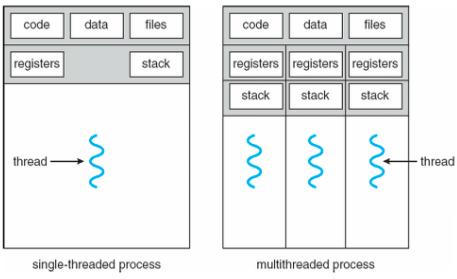
- 스레드는 곧 함수이며, 따라서 프로세스는 반드시 1개 이상의 프로세스로 구성됨
- 메인 스레드(main): 프로세스 생성될 때 OS에 의해 자동으로 생성된 최초 1개의 스레드
- 멀티 스레드: 하나의 컨테이너가 여러 개의 스레드를 가진 것
- 다른 스레드들은 함수를 스레드로 만들어줄 것을 요청하여 생성된다.
- 각 스레드별로 TCB(Thread Control Block)가 생성되며, TCB는 PCB에 등록된다.
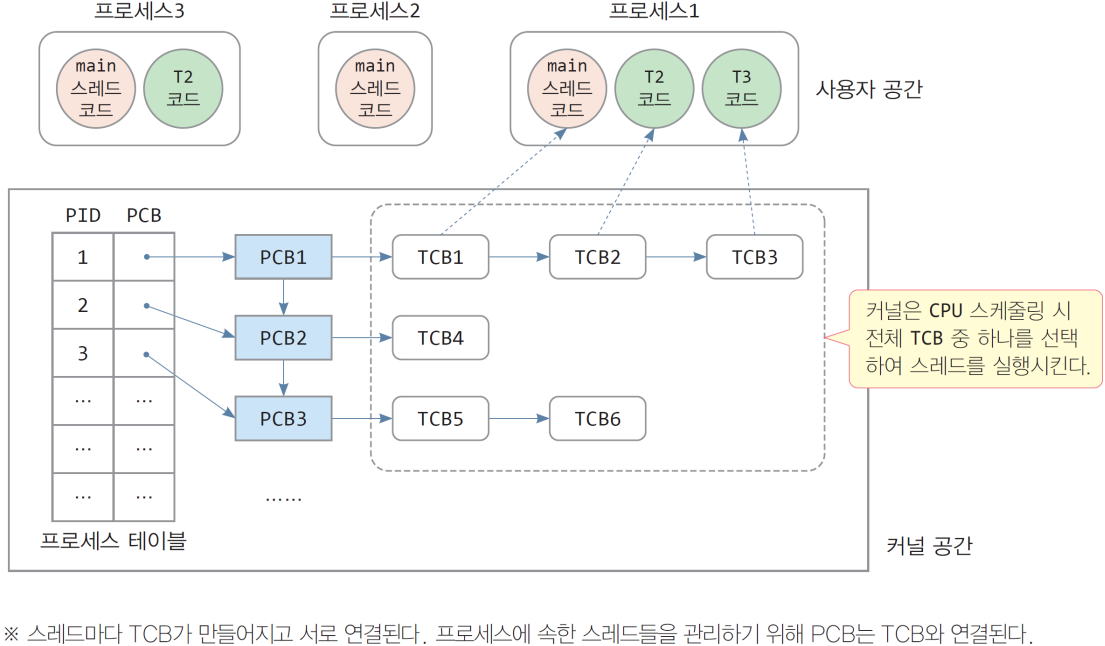
- 프로세스는 스레드들의 공유 공간(환경)을 제공함
- 모든 스레드는 프로세스의 코드, 데이터, 힙을 공유함
- 스레드 사이 통신이 용이
- 모든 스레드는 프로세스의 코드, 데이터, 힙을 공유함
2.1. 스레드/프로세스 생명
- 스레드 종료 시점: 스레드로 만든 함수가 종료될 때
- 스레드가 종료되면 TCB도 제거된다.
- 프로세스 종료 시점: 프로세스에 속한 모든 스레드가 종료될 때
- 프로세스가 강제로 종료되면 스레드도 당연히 종료된다.
2.2. 스레드 예제 (for xNIX OS)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
#include <pthread.h> // pthread lib
#include <stdio.h>
#include <stdlib.h>
//쓰레드 간 동시 접근
int sum = 0; // global variable
//20만번(count)만큼 실행
void *myThread1(void *p) { // for the thread 1
printf("\t myThread 1 starts\n");
int *i = (int *)malloc(sizeof(int));
for (i = 0; i < (*(int *)p); i++)
sum += 1;
return (void *)i;
}
void *myThread2(void *p) { // for the thread 2
printf("\t myThread 2 starts \n");
int *i = (int *)malloc(sizeof(int));
for (i = 0; i < (*(int *)p); i++)
sum -= 1;
return (void *)i;
}
int main() {
pthread_t tid1, tid2; // thread id
int count = 200000;
int *ret1, *ret2;
// create thread (id, attribute, function_pointer, argument)
pthread_create(&tid1, NULL, myThread1, &count);
printf("myThread1's tid: %0X \n", (int)tid1);
pthread_create(&tid2, NULL, myThread2, &count);
printf("myThread2's tid: %0X \n", (int)tid2);
pthread_join(tid1, (void **)&ret1); // waiting for 'tid1'
pthread_join(tid2, (void **)&ret2); // waiting for 'tid2'
printf("myThreads have been finished \n");
printf("sum = %d\n", sum);
printf("ret1 = %d\n", (int)ret1);
printf("ret2 = %d\n", (int)ret2);
return 0;
}
실행 결과
1
2
3
4
5
6
7
8
myThread1's tid: CC38A640
myThread2's tid: CBB89640
myThread 1 starts
myThread 2 starts
myThreads have been finished
sum = 0 ## 이 값이 0일 수도 아닐 수도 있다.
ret1 = 200000
ret2 = 200000
2.2.1. 생각해보아야 할 점
- 프로세스는 스레드들간 공유 자원을 제공한다.
- Data 영역은 확실히 공유되며, Stack 영역은 각자 별개로 가진다.
하지만 스레드의 실행 순서는 알 수 없다!
- 공유 자원(전역변수) 합이 0이 되지 않는다.
- 하나의 자원을 여럿이서 쓰려 하면 문제가 발생한다 → OS의 문제
2.3. 스레드 장점
- CPU 응답성 향상
- 자원 공유, 효율성 향상
- 다중 CPU의 운용 용이
2.4. 스레드 단점
- 모든 자원을 공유한다는 것 → 하나의 스레드만 잘못되도 프로세스 전체가 모두 죽어버릴 수 있다!
- 너무 많은 스레드 → 너무 많은 context switching
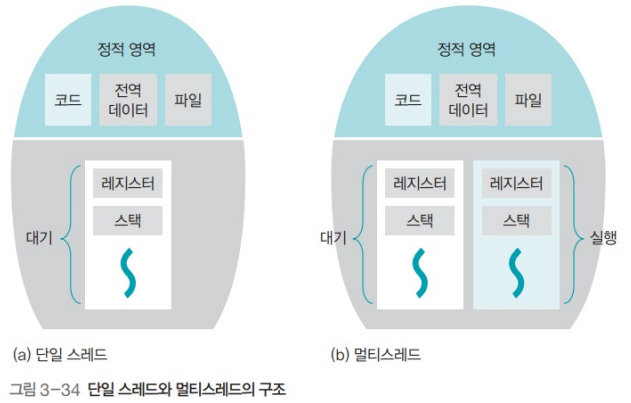
3. 스레드 주소 공간
스레드 주소 공간이란 스레드가 생성/실행되는 동안 접근 가능한 메모리 영역으로, 프로세스의 주소 공간 내에 형성된다.
3.1. 스레드 사적 공간
- 스레드 코드(Thread code)
- 스레드 로컬 스토리지(TLS, Thread Local Storage)
- 스레드 스택
3.2. 스레드 사이의 공유 공간
- 프로세스 코드
- 프로세스의 데이터 공간(로컬 스토리지 제외)
- 프로세스 힙 영역
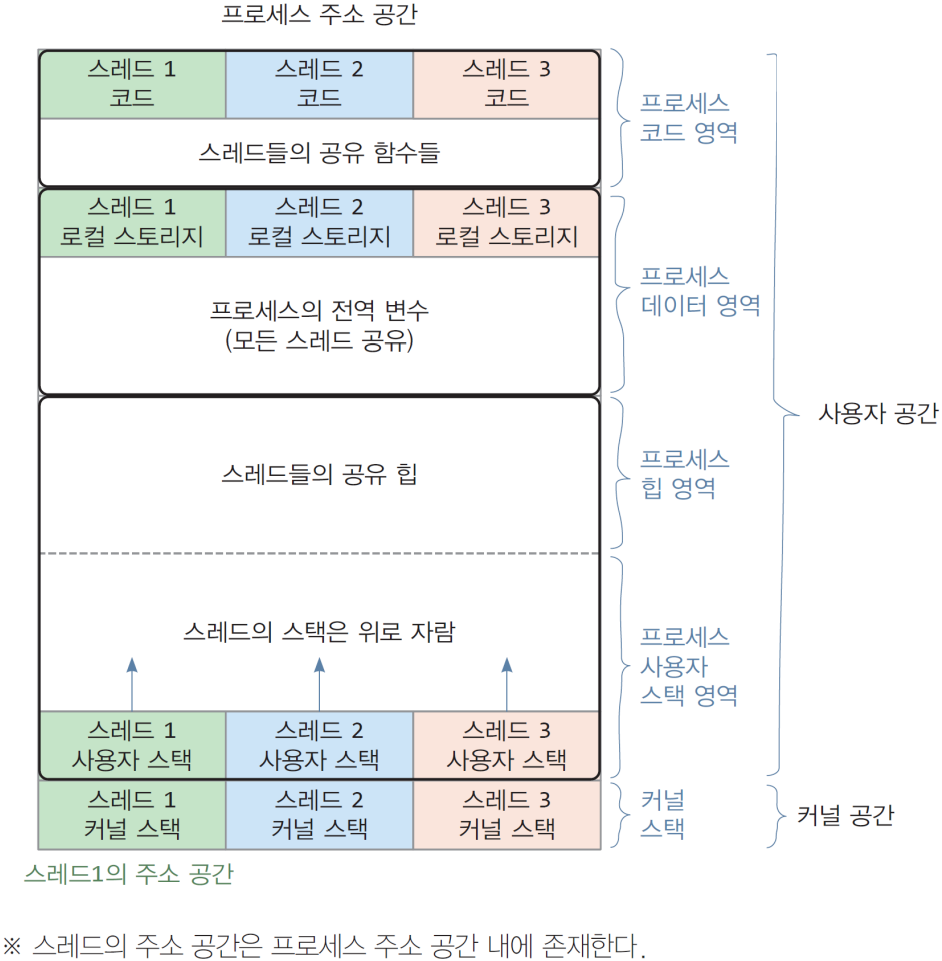
TLS example (for xUNIX OS)
__thread: 스레드 로컬 스토리지임을 선언하는 키워드이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
#include <pthread.h> // pthread lib
#include <stdio.h>
#include <stdlib.h>
int gsum = 0;
int __thread tsum = 1; //__thread: 로컬 스토리지임을 선언하는 키워드이다.
void func(int a) {
printf("5_%d. gsum= %d / tsum= %d \n", a, gsum, tsum);
int b = a + 10;
gsum += b;
tsum += b;
printf("6_%d. gsum= %d / tsum= %d \n", a, gsum, tsum);
}
void *myThread(void *p) {
int a = (*(int *)p);
printf("2_%d. gsum= %d / tsum= %d \n", a, gsum, tsum);
for (int i = 0; i < 30000000 / a; i++)
;
gsum += a;
tsum += a;
printf("3_%d. gsum= %d / tsum= %d \n", a, gsum, tsum);
func(a);
printf("7_%d. gsum= %d / tsum= %d \n", a, gsum, tsum);
}
int main() {
pthread_t tid[2];
int arg[2] = {1000, 3000};
printf("1_main. gsum= %d / tsum= %d \n", gsum, tsum);
pthread_create(&tid[0], NULL, myThread, &arg[0]);
pthread_create(&tid[1], NULL, myThread, &arg[1]);
pthread_join(tid[0], NULL);
pthread_join(tid[1], NULL);
printf("8_main. gsum= %d / tsum= %d \n", gsum, tsum);
return 0;
}
실행 결과
1
2
3
4
5
6
7
8
9
10
11
12
13
# 실행시마다 출력이 바뀐다.
1_main. gsum= 0 / tsum= 1
2_3000. gsum= 0 / tsum= 1
3_3000. gsum= 3000 / tsum= 3001
5_3000. gsum= 3000 / tsum= 3001
6_3000. gsum= 6010 / tsum= 6011
7_3000. gsum= 6010 / tsum= 6011
2_1000. gsum= 0 / tsum= 1
3_1000. gsum= 7010 / tsum= 1001
5_1000. gsum= 7010 / tsum= 1001
6_1000. gsum= 8020 / tsum= 2011
7_1000. gsum= 8020 / tsum= 2011
8_main. gsum= 8020 / tsum= 1
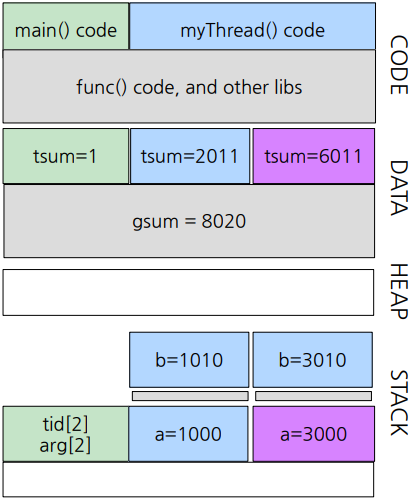 실행 결과 참고 도표
실행 결과 참고 도표
4. 스레드 Lifecycle
스레드 라이프사이클은 프로세스의 것과 흡사하며, TCB로 관리한다.
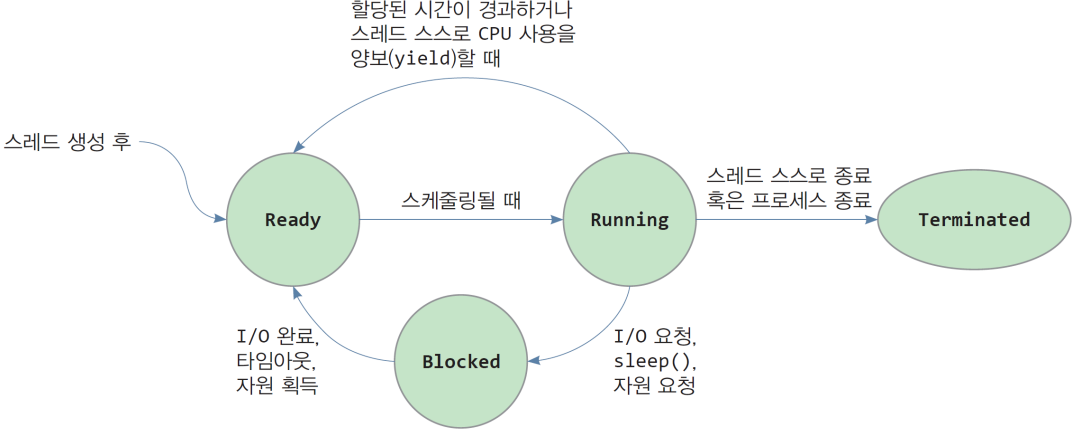
4.1. 스레드의 상태 변화
| 스레드 상태 | 설명 |
|---|---|
| 준비 상태(Ready) | 스레드가 스케줄 되기를 기다리는 상태 |
| 실행 상태(Running) | 스레드가 CPU에 의해 실행 중인 상태 |
| 대기 상태(Blocked) | 스레드가 입출력 요청하거나 sleep()과 같은syscall로 인해 커널에 의해 중단된 상태 |
| 종료 상태(Terminated) | 스레드가 종료된 상태 |
5. 스레드 Operation
5.1. 스레드 생성
- 스레드는 스레드 생성하는 syscall이나 라이브러리 함수를 호출하여 다른 스레드를 생성할 수 있음
- 프로세스 생성 시 자동으로 main 스레드 생성됨
5.2. 스레드 종료
- 프로세스 종료와 스레드 종료의 구분이 필요하다.
5.2.1. 프로세스 종료
- 프로세스에 속한 어떤 스레드라도
exit()syscall 부르면 프로세스 종료(모든 스레드 종료) - 메인 스레드의 종료(C언에서
main()의 종료) → 모든 스레드도 함께 종료
5.2.2. 스레드 종료
pthread_exit()와 같이 스레드만 종료하는 syscall 호출 시 해당 스레드만 종료됨main()에서pthread_exit()부르면 역시 main 스레드만 종료(다른 스레드는 남아있음 → 프로세스가 살아있음)
5.3. 스레드 조인(join)
- 스레드가 다른 스레드가 종료할 때까지 대기하는 것
- 주로 부모 스레드가 자식 스레드의 종료를 대기한다.
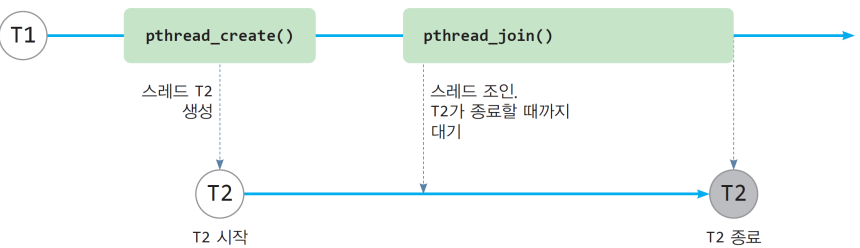 스레드의 조인
스레드의 조인
5.4. 스레드 양보(yield)
- 스레드가 자발적으로
yield()syscall 호출을 통해 자신의 실행을 중단하고 다른 스레드를 스케줄하도록 양보(지시)하는 것
6. Thread Context
스레드의 실행중인 상태 정보들은 TCB(Thread Control Block)에 저장이 된다.
6.1. Thread Control Block(TCB)
- 스레드 생성 시 커널에 의해 만들어진다.
- 스레드 소멸 시 같이 사라진다.
- 각종 CPU 레지스터의 값을 관리한다.
- PC: 실행 중인 코드 주소
- SP/BP: 실행 중 함수의 스택 주소
- Flag: 현재 CPU의 상태 정보
- 등
나머지 메모리들은 어차피 공유되기 때문에, 레지스터만 저장해 두면 필요할 때 CPU에 복귀하면 이전에 실행하던 상태로 돌아갈 수 있다.
| 구분 | 요소 | 설명 |
|---|---|---|
| 스레드 정보 | tid | 스레드 ID 스레드가 생성될 때 부여된 고유 번호 |
| state | 스레드의 상태 정보 Running, Ready, Blocked, Terminated 가능 | |
| 컨텍스트 | PC | CPU의 PC 레지스터 값 |
| SP | CPU의 SP 레지스터 값 | |
| 다른 레지스터들 | 스레드 중지 당시 레지스터의 여러 값들 | |
| 스케줄링 | 우선순위 | 스케줄링 우선순위 |
| CPU 사용 시간 | 스레드 생성 이후 CPU 사용시간 | |
| 관리를 위한 포인터들 | PCB 주소 | 스레드 속한 프로세스의 PCB 주소 |
| 다른 TCB에 대한 주소 | 이웃 스레드를 연결하기 위한 링크 | |
| 블록 리스트/준비 리스트 등 | 입출력 대기하고 있는 스레드 연결하는 TCB 링크 준비상태에 있는 스레드 연결하는 TCB 링크(스레드 스케줄링 시 사용) 등 |
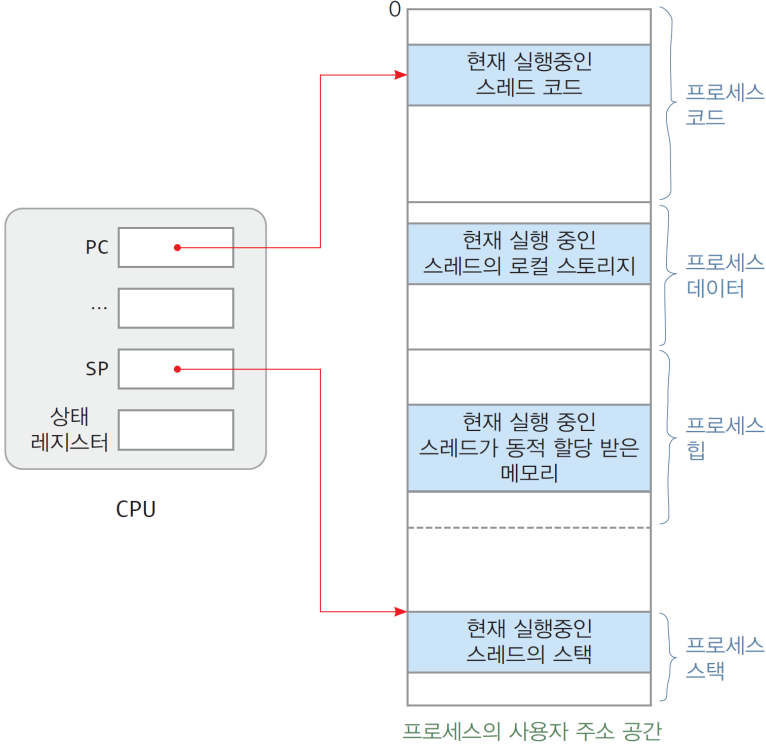 TCB의 도식화
TCB의 도식화
7. Thread Context Switching(a.k.a. thread switching)
- 현재 실행중인 스레드를 중단시키고, 다른 스레드에 CPU를 할당하는 과정
- 현재 CPU 컨텍스트를 TCB에 저장하고, 다른 TCB에 저장된 컨텍스트를 CPU에 적재함으로서 구현된다.
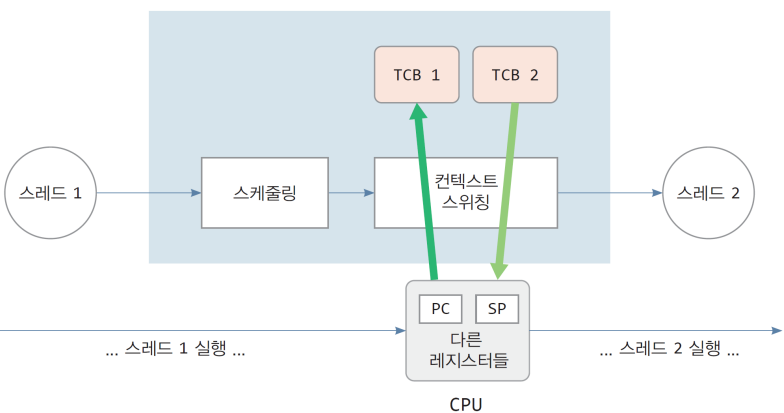 Thread Switching 과정
Thread Switching 과정
7.1. CPU 레지스터 저장 및 복귀
- 현재 실행 중인 스레드 A의 컨텍스트를 TCB-A에 저장
- TCB-B에 저장된 스레드 B의 컨텍스트를 CPU에 적재
- PC가 복구됨으로서, CPU는 스레드 B가 이전에 중단된 위치에서 실행 재개가 가능하다.
- SP가 복구됨으로서, 자신의 이전 스택을 되찾게 된다.
- 스택에는 이전 중단 시 실행하던 함수 매개변수/지역변수들이 그대로 저장되어 있음
7.2. 커널 정보 수정
- TCB-A와 TCB-B에 스레드 상태정보와 CPU 사용 시간 등을 수정
- TCB-A를 준비 리스트나 블록 리스트로 옮김
- TCB-B를 준비 리스트에서 분리
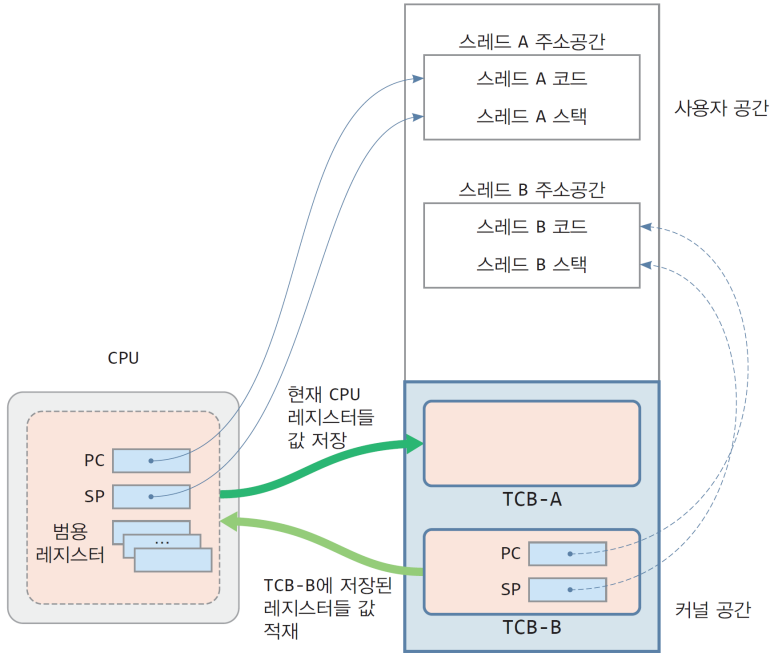 Thread Switching 과정 2
Thread Switching 과정 2
8. Thread Context Switching의 오버헤드
- Context Switching은 상당히 비싼 작업: CPU의 본래 할 일 못하고 다른 작업에 리소스를 빼앗긴다.
- 문맥 교환 시간 길거나 잦은 경우, 컴퓨터 처리율이 심각하게 저하될 수 있음
8.1. 동일 프로세스의 다른 스레드로 스위칭되는 경우
- 컨텍스트 저장 및 복귀
- 현재 CPU의 컨텍스트(PC, SP 등)를 TCB에 저장
- TCB로부터 스레드 컨텍스트를 CPU에 복귀
- TCB 리스트 조작
- 캐시 Flush와 채우기 시간 소요
8.2. 다른 프로세스의 스레드로 스위칭되는 경우
- 다른 프로세스로 교체되면, CPU가 실행하는 주소 공간이 바뀌는 큰 변화로 인해 추가적인 오버헤드가 발생한다.
- 추가적인 메모리 오버헤드
- 시스템 내에 현재 실행 중인 프로세스의 매핑 테이블을 새 프로세스의 매핑 테이블로 교체한다.
- 추가적인 캐시 오버헤드
- 프로세스 바뀌므로 CPU 캐시에 담긴 코드와 데이터가 무력화된다.
- 새 프로세스의 스레드가 실행 시작하면 CPU 캐시 미스 발생한다. → 다시 캐시 채워지는데 상당한 시간 소요
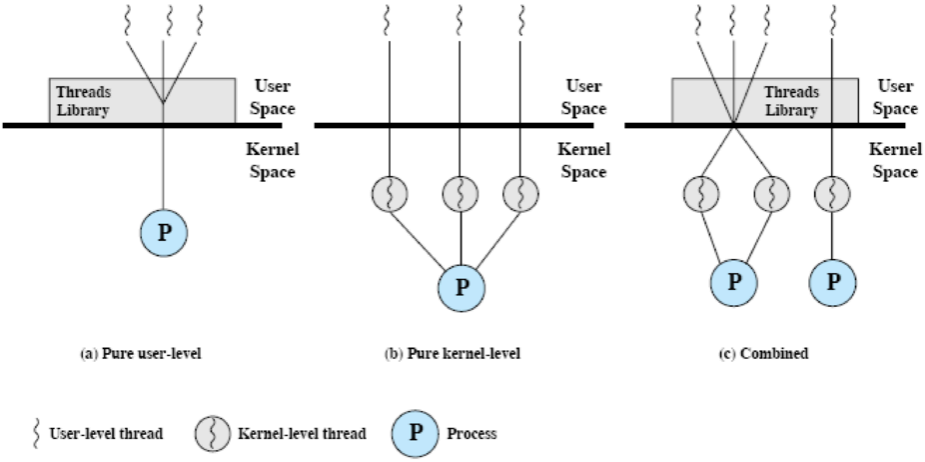
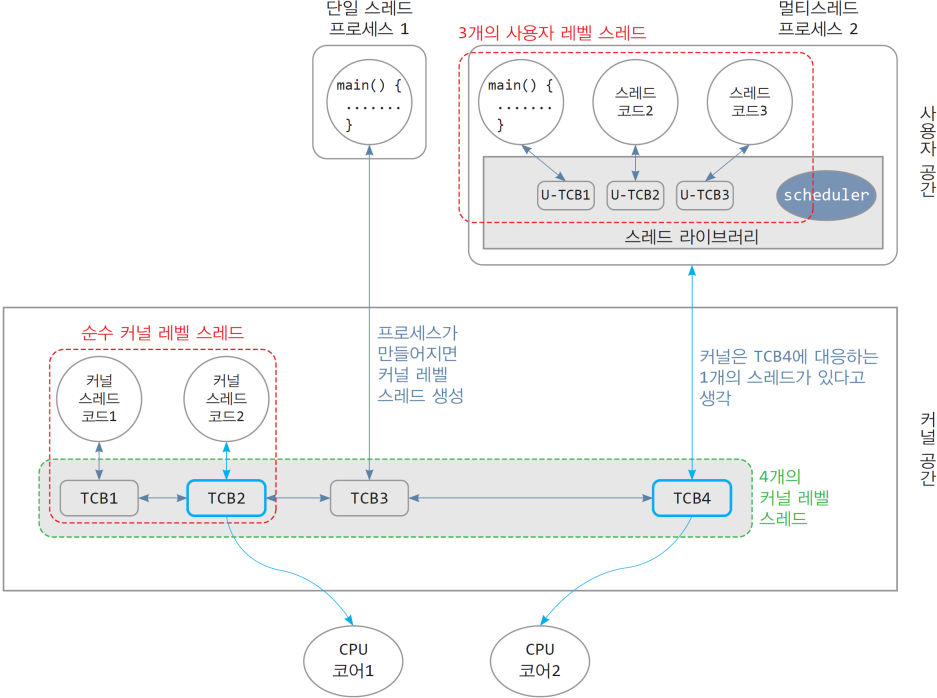
9. 스레드 모델: 멀티스레딩 모델
9.1. 스레드의 타입
- Kernel-level thread
- OS가 커널에서 관리하는 스레드
- User-level thread
- User-space에서 관리하는 스레드
9.2. Kernel-level Thread
커널이 직접 생성하고 관리하는 스레드
- 응용프로그램이 syscall 통해 커널 레벨 스레드 생성
- 커널 스레드에 대한 정보(TCB)는 커널 공간에 생성하고 공유
- 즉 커널에 의해 스케줄된다.
- 스레드 주소 공간(스레드 코드 & 데이터): 사용자 공간에 존재
- main thread는 커널 스레드
- 응용프로그램 적재되어 프로세스 생성될 때, 자동으로 커널은 main 스레드 생성
9.2.1. Pure(순수) Kernel-level Thread
- 부팅 때부터 커널의 기능 돕기 위해 만들어진 스레드
- 커널 코드 실행하는 스레드
- 스레드 주소 공간은 모두 커널 공간에 형성됨
- 커널 모드에서 작동되며, 사용자 모드에서 실행되는 일은 없음
9.3. User-level Thread
라이브러리에 의해 구현된 일반적인 스레드
- 응용프로그램이 라이브러리 함수 호출하여 사용자 레벨 스레드 생성
- 스레드 라이브러리가 스레드 정보(U-TCB)를 사용자 공간에 생성하고 소유
- 스레드 라이브러리는 사용자 공간에 존재
- 스레드 라이브러리에 의해 스케줄됨
- 커널(OS)은 이들의 존재에 대해 알 수 없음 → 하나의 프로세스로만 인식함
- 스레드 주소 공간(스레드 코드 & 데이터): 사용자 공간에 존재
9.4 Multithreading models
- 멀티스레드의 구현
- 응용 프로그램에서 작성한 스레드가 시스템에서 실행되도록 구현하는 방법
- 사용자가 만든 스레드가 시스템에서 스케줄되고 실행되도록 구현하는 방법
- 스레드 라이브러리와 커널의 syscall의 상호 협력 필요
- 응용 프로그램에서 작성한 스레드가 시스템에서 실행되도록 구현하는 방법
9.4.1. Many-to-One(N:1) model
- N개의 사용자 레벨 스레드 ↔ 1개의 커널 레벨 스레드 매핑
9.4.2. One-to-One(1:1) model
- 1개의 사용자 레벨 스레드 ↔ 1개의 커널 레벨 스레드 매핑
9.4.3. Many-to-Many(N:M) model
- N개의 사용자 레벨 스레드 ↔ M개의 커널 레벨 스레드 매핑
비교
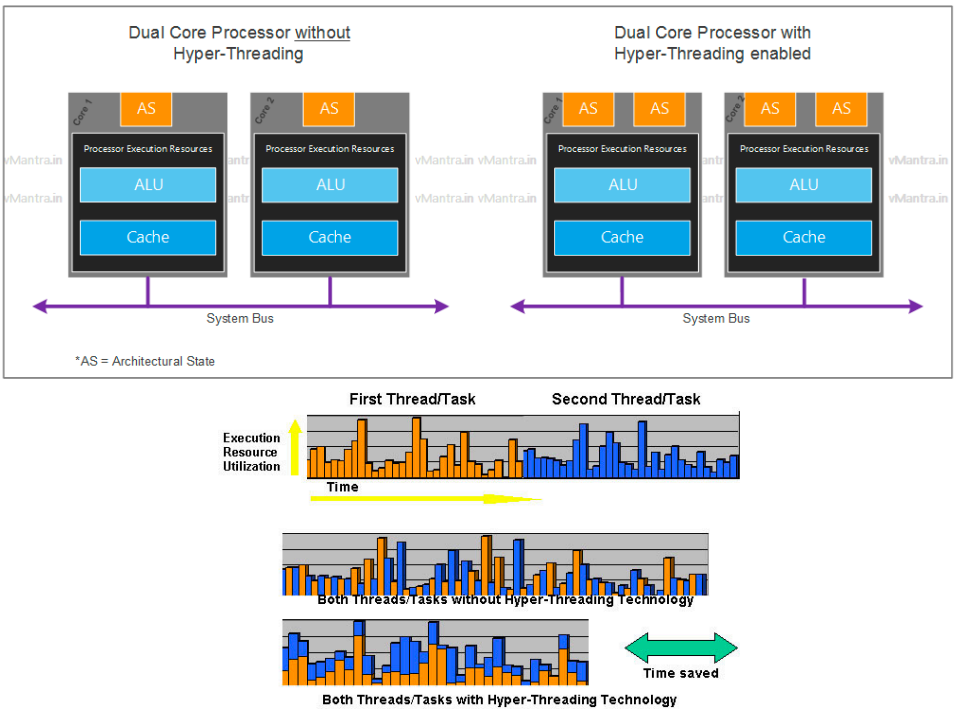
참고: SMT(Simultaneous multithreading)
- a.k.a., 하이퍼스레딩(Hyper-threading)
10. 추가적인 스레드 이슈
10.1. 멀티스레드와 fork()와 exec()
- 멀티스레드에서
fork()또는exec()syscall을 실행한다면 어떻게 되는 것인가?- 여러 스레드 중 한 스레드가
fork()호출하는 경우- 새 프로세스는
fork()를 호출한 스레드만 복제한다.
- 새 프로세스는
- 여러 스레드 중 한 스레드가
exec()호출하는 경우- 프로세스 전체가 사라진다.
- 여러 스레드 중 한 스레드가
- 그러면, fork()가 모든 스레드를 복제한다면 어떻게 되는 것인가?
- 일부 시스템은 전체 스레드를 복제하는 fork도 존재한다. 그러나,
fork()호출 이후exec()호출시: 모든 스레드 복제한 의미가 없음fork()호출 이후exec()미호출시: 모든 쓰레드 복제가 의미 있음
- 일부 시스템은 전체 스레드를 복제하는 fork도 존재한다. 그러나,
10.2. 자원 동기화 문제: thread-safe 개념
하나의 자원에 대해 여러 스레드가 동시에 접근하면 공유 데이터 훼손 문제가 발생하게 된다.
- Thread-safe
- 멀티스레드 프로그래밍에서 어떤 함수/변수/객체가 여러 스레드로부터 동시 접근이 이뤄져도 프로그램의 실행에 문제가 없는 것
10.2.1. Thread-safe를 지키는 방법
- Re-entrancy
- 어떤 함수가 한 스레드에 의해 호출되어 실행중일 때, 다른 스레드가 그 함수 호출하더라도 결과가 각각에게 올바르게 주어져야 함
- Thread-local storage
- 공유 자원의 사용을 최대한 줄여 각 스레드에서만 접근 가능한 저장소들을 사용, 동시 접근을 막음
- 동기화 방법과 관련되어 있고, 공유상태 피할 수 없을 때 사용하는 방법
- Mutual exclusion
- 공유 자원 꼭 사용해야 할 경우 그 자원의 접근을 세마포어 등의 락으로 통제
- Atomic operations
- 공유 자원에 접근할 때 원자 연산을 이용하거나 ‘원자적’으로 정의된 접근 방법을 사용함으로써 상호 배제 구현
각주
이 포스팅은 작성자의 CC BY-NC 4.0 라이선스를 준수합니다.