[DB] 관계 데이터 모델
1. 관계 데이터 모델 개념
1.1. 릴레이션(relation)
- relation: 행과 열로 구성된 테이블
| 용어 | 한글 용어 | 비고 |
|---|---|---|
| relation | 릴레이션, 테이블 | “관계”라고 하지 않음 |
| relational data model | 관계 데이터 모델 | |
| relational database | 관계 데이터베이스 | |
| relational algebra | 관계대수 | |
| relationship | 관계 |
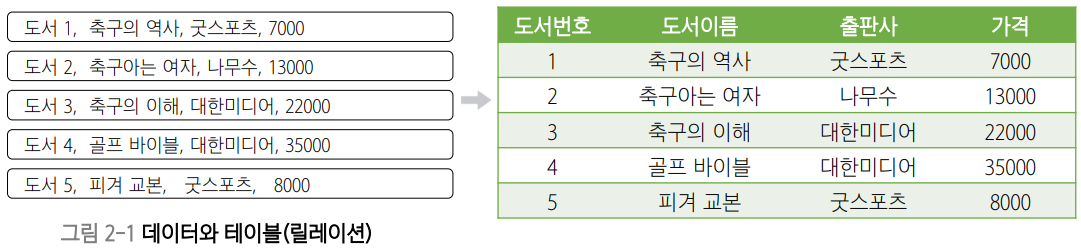
- 도서번호 = {1, 2, 3, 4, 5}
- 도서이름 = {축구의 역사, 축구아는 여자, 축구의 이해, 골프 바이블, 피겨 교본}
- 출판사 = {굿스포츠, 나무수, 대한미디어}
- 중복이 없음
- 가격 = {7000, 13000, 22000, 35000, 8000}
첫 번째 행(1, 축구의 역사, 굿스포츠, 7000)의 경우 네 개의 집합에서 각각 원소 한 개씩 선택하여 만들어진 것으로, 이 원소들이 관계(relationship)를 맺고 있다.
1.2. 관계(relationship)
- 릴레이션 내에서 생성되는 관계
- 릴레이션 내 데이터들의 관계
- 릴레이션 간 생성되는 관계
- 릴레이션 간 관계(참조로 관계 생성)
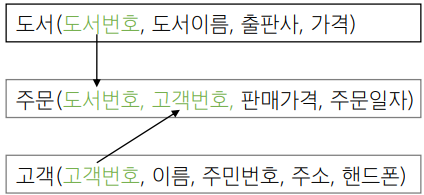 릴레이션 간의 관계
릴레이션 간의 관계
2. 릴레이션 스키마와 인스턴스
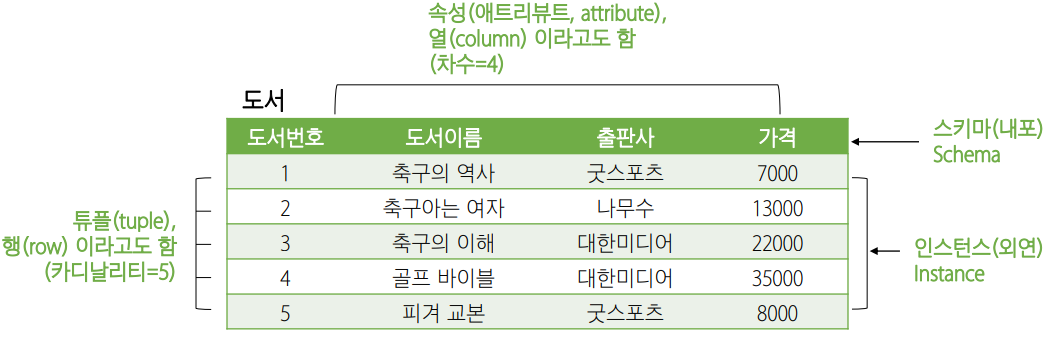 도서 릴레이션
도서 릴레이션
2.1. 릴레이션 스키마
- 스키마의 요소
- 속성(attribute): 릴레이션 스키마의 열
- 도메인(domain): 속성이 가질 수 있는 값의 집합
- 차수(degree): 속성의 개수
- 스키마의 표현
릴레이션 이름(속성1, 속성2, 속성3, ...)- 예) 도서(도서번호, 도서이름, 출판사, 가격)
- 혹은
릴레이션 이름(속성1: 도메인1, 속성2: 도메인2, 속성3: 도메인3, ...)- 예) 도서(도서번호: integer, 도서이름: char(40), 출판사: char(40), 가격:integer)
2.2. 릴레이션 인스턴스
- 인스턴스 요소
- 튜플(tuple): 릴레이션의 행
- 카디날리티(cardinality): 튜플의 수
2.3. 릴레이션 구조와 관련된 용어
| 릴레이션 용어 | 같은 의미로 통용되는 용어 | 파일 시스템 용어 |
|---|---|---|
| 릴레이션(relation) | 테이블(table) | 파일(file) |
| 스키마(schema) | 내포(intension) | 헤더(header) |
| 인스턴스(instance) | 외연(extension) | 데이터(data) |
| 튜플(tuple) | 행(row) | 레코드(recored) |
| 속성(attribute) | 열(column) | 필드(field) |
3. 릴레이션 특징
- 속성의 값은 단일 값을 가짐
- 속성은 서로 다른 이름 가짐
- 한 속성 값은 모두 그 속성에서 정의한 도메인 값만 가질 수 있음
- 속성의 순서는 상관 X
- 릴레이션 내 중복 튜플 허용 X
- 튜플 순서는 상관 X
- 관계 데이터 모델은 데이터를 릴레이션으로 표현함
- 릴레이션의 제약조건과 관계 연산 위한 관계대수를 정의
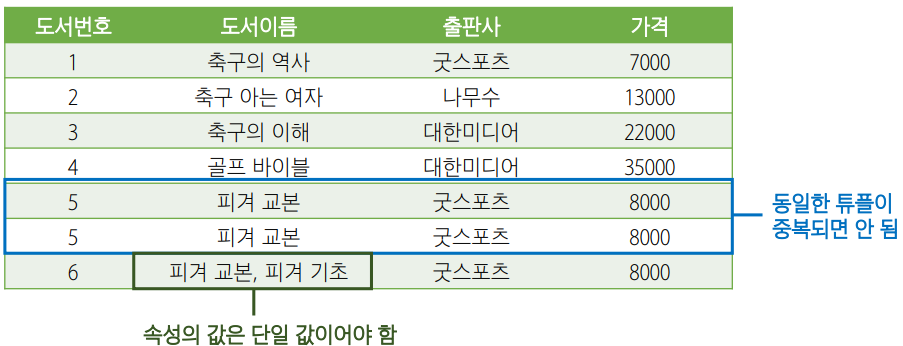 릴레이션 특징이 위배된 경우
릴레이션 특징이 위배된 경우
4. 관계 데이터 모델
- 관계 데이터 모델은 데이터를 2차원 테이블 형태인 릴레이션으로 표현함
- 릴레이션에 대한 제약조건과 관계 연산을 위한 관계대수를 정의함
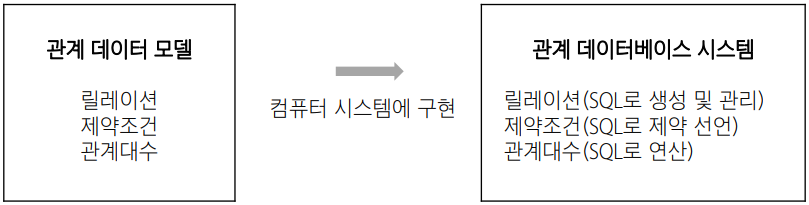 관계 데이터베이스 시스템
관계 데이터베이스 시스템
이 포스팅은 작성자의 CC BY-NC 4.0 라이선스를 준수합니다.